昨今話題になっている「生成AI(generative AI)」とは、訓練されたデータに基づき、テキスト・画像・動画・プログラミングコード・データなどの出力を生成してくれるAIのことを指します。現在主流なのは、インターネット上の大量のデータに基づき「大規模言語モデル」と呼ばれるモデルを訓練し、これに入力を与える方式です。大規模言語モデルによる生成AIは、実は以前から言語翻訳のために「LLM(Large Language Model)」として研究されてきましたが、下記の4つのブレークスルーが起き、一気に注目を浴びるようになりました。
- 2017年にGoogleがAttention機構を使ったTransformerを発表
- Scaling Law(パラメータ量を大きくするほど精度が上がる)の発見
- 人間のフィードバックによる強化学習と、人間の会話を使ったファインチューニング
- ChatGPTのようなチャットインタフェースを持ったサービスの一般公開
代表的な生成AI技術と特徴
代表的な生成AIサービスには次のようなものがあります。(2023年6月時点)

- 対話型生成AIサービス
(GPTベース) 
- 対話型生成AIサービス
(Googleの大規模言語モデルを活用) - Amazon Bedrock
- AI運用サービス
(複数モデルに対応) - DreamStudio
- 画像生成サービス
(Stable Diffusionモデル)
また、大規模言語モデルには次のようなものがあり、それぞれ特徴があります。
- Amazon Titan
- 不適切入力を検出拒否するところを強化。
- Jurassic-2
- AI21 Studio’sの優れた品質、柔軟性、高いパフォーマンスを誇るとされる言語モデル。
- PaLM
- Googleの5400億パラメータモデル、大きくて遅い。
- GLaM
- 1.2兆パラメータモデル。MoE(Mixture of Expert)モデルを採用。
- LaMDA
- Googleが発表した対話用途向けの大規模言語モデル。Bardの初期基盤モデルとして使われた。
- Gopher
- Google子会社のDeepMindの2800億パラメータの言語モデル。
- Megatron-Turing NLG
- MicrosoftとNVIDIAが生んだ5300億パラメータの言語モデル。
- LLaMA
- Metaの言語モデル。70億~650億の4種類のパラメータが選べる。小型で高性能。
- GPT3.5
- パラメータ数は1750億とも3500億とも言われています。ファインチューニングに特徴あり。(GPT4はパラメータ数未公開)
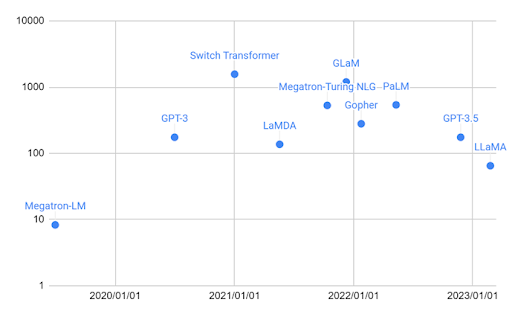
生成AIはGoogle、Meta(Facebook)、Amazonなど各社が発表しており、パラメータ数が多い(巨大)イコール高性能ではない事に注意が必要です。基本的にトレードオフ関係である性能と精度について、用途を考えた時に「どの程度のバランスが良いか」を元に選定する事が重要となります。
生成AIにできること・できないこと・させてはいけないこと
生成AIには「できること」「できないこと」と、法令や倫理面から「させてはいけないこと」があります。生成AIの活用を考えている場合、このような点にも留意する必要があります。生成AIの大規模言語モデルとは 「膨大な知識・言語化能力・卓越した対人能力」この特性を理解して使いこなす事に尽きます。
以下はその一例です。
- できること
-
- 訓練されたデータに基づき、質問に答える
- 要約する、言い換える、翻訳する
- 人間と対話する
- アイディアを出す
- プログラムを書く
- プログラムのコメントを書く
- 絵を描く、詩を書く、音楽を作曲する
- できないこと
- 新規や非公開の情報など、言語モデルの学習データに含まれない事項への回答(別途提供が必要)
- させてはいけないこと
-
- 医療や投資のアドバイスなど法令に違反すること
- 倫理的、道徳的に問題がある質問に答えること
企業にとっての生成AIの価値
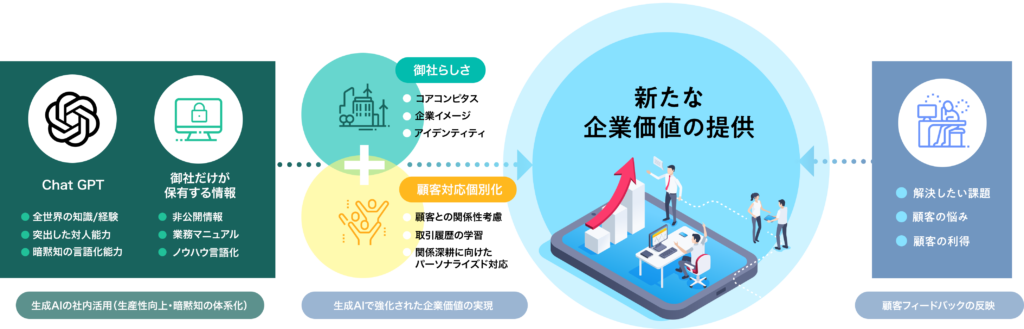
ACCESSでは「生成AIを活用するステップ」は「企業の価値創造のステップ」であると考えています。生成AIに「自社だけが保有する情報を学習」させれば、市場+顧客への新たな企業価値を提供することが可能です。ACCESSは実際にこのようなアプローチの下で、自社製品にGPTモデルを利用して新たな価値を創造する取り組みを行っています。
ACCESS、ChatGPTを利用し、「Linkit®」と「CROS®」のサービスを強化し、法人向け「問い合わせ対応自動化」支援サービスを提供開始
生成AIを利用したプロトタイプを作る
生成AIは新技術であることから、自社製品などへの組み込みにはまだまだハードルが高いと思われます。このような場合、通常は調査を始め試験導入・評価を実施し検討を重ねていくことになりますが、実際にACCESSでも先述の取り組みまでの間には、生成AIを利用した様々なプロトタイプ(試作品)を開発し評価・検証を重ねてきました。
- 社内規定・就業規則などの問い合わせ自動化
- 通販システムの外部操作マニュアルの問い合わせ自動化
- AIの個性を設定した、キャラクタ作成と自動読み上げ
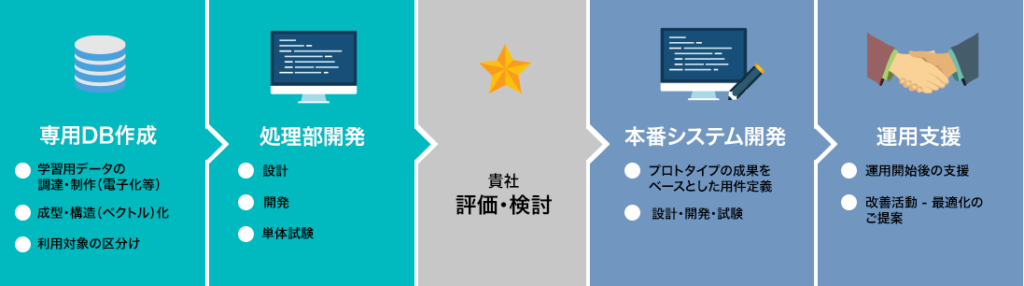
自社製品への導入可能性を模索していて、試験導入・評価をお考えの場合、このような具体的なプロトタイプ開発を当社がお手伝いいたします。例えば「問い合わせ自動化」をしてくれるQ&A Bot/Chatプロトタイプはこのような流れで作り上げていきます。
- 貴社が保有するドキュメント・データなどのナレッジをACCESSに提供頂き、ACCESSが所定の形式のテキストデータに成型・構造化しGPT-4モデルで利用可能な専用DBを作成します。
- GPT-4モデルにプロトタイプ利用者からの質問(Q)を入力・解析し、専用DBの情報と組み合わせて自然な言葉で回答(A)を出力します。
- 入出力には利用が平易なSlackのBotを利用し、会話にはSlackを利用する事でChatGPTライクなプロトタイプを作ります。
プロトタイプが利用するインフラ・サービス(Slack、OpenAI、AWSなど)のアカウント取得、利用料清算はACCESSで代行いたしますので、貴社のご対応は「保有するドキュメント・データなどのナレッジを提供するのみ」となります。
プロトタイプ開発から製品への組み込みまで
プロトタイプはご契約から最短1か月で納入できます。貴社の保有するデータ状況や利用方法などの条件に合わせて、2つのプランを用意しています。
- クイックスタートプラン(所要期間1か月)
-
- GPTで試してみたいデータがPDF(テキスト)やHTMLで存在し、すぐに提供可能。
- Slackを使うことに社内的なハードルは特にない。(社内承認等)
- データは提供可能だがSlackが利用不可という場合、クイックスタートプランのままで代替となるACCESSのチャット製品(Linkit)にてのご提供・利用も可能です。
- 手元で評価できるものが可能な限り早く欲しい。
- アドバンスドプラン(所要期間2か月)
-
-
GPTで試してみたいデータが整理できていない。または大量のデータを使って試してみたい。
- ACCESSにてデータ作成の支援を行います。
- クイックスタートプランよりも専用DBの情報量を増やすことができます。
-
Slackは社内ルール上使えない、または利用条件がある。(Teams等の指定なども含む)
- Slack Bot/Chat以外のプロトタイプ形態について、2か月内で可能な限りの範囲の物を検討し構築いたします。
-
プロトタイプの完成後は貴社内で評価いただき、自社製品・本番システム等への組み込み検討を行っていただきます。評価・検討後の自社製品・本番システム等への組み込みには、プロトタイプ開発での知見を活かすことでスムーズな移行が可能です。
また、生成AIを利用した製品・システムの運用では従来とは異なる観点での検討・整理が必要になる点も注意が必要です。ACCESSではこのような点も自社での運用経験を踏まえ支援いたします。
- ガイドライン策定(登録・管理・精算・利用方法・注意事項)
-
- 個人利用のガイドライン
- 会社での機密情報を含まない利用のガイドライン
- 業務データ利用のガイドライン
- アプリ外部公開のガイドライン
- 課金管理
-
- 従量課金への対応
- 精算方法(請求書支払い対応)
- データ管理
-
- 業務利用の範囲の設定
- 業務利用の場合のデータの利用範囲の確認
- 秘密情報の扱い(識別、除外)
- 情報更新方法、頻度の管理
- 法的課題
- セキュリティ
-
- アプリ組み込みでのセキュリティ対策
- プロンプトインジェクション
- プロンプトリーキング
- ジェイルブレイキング
- アカウント管理
-
- OpenAIへのアカウント設定
- 個人登録でない場合のアカウント管理方法
- 運用
-
- セキュリティ研修
- 利用方法周知徹底
- 情報更新プロセス
- ログ管理
まとめ
本記事では各生成AIの特徴の解説から、新たな企業価値を創造するための活用ステップとして、自社保有のナレッジを学習させたプロトタイプ開発・評価をご紹介しました。
自社製品などへの組み込みを最終目的とした、生成AIの評価としてプロトタイプ開発にご興味がありましたら、お問い合わせよりお気軽にご連絡ください。