近年、大規模言語モデル(LLM)やVision-Language Models(VLM)の目覚ましい進展を背景に、AIはより高度な情報処理能力を獲得してきました。これらの進歩を背景に、物理世界でタスクを実行するEmbodied AI(具体化された人工知能)の分野では、新たな潮流として「Vision-Language-Action Models(VLA)」が注目を集めています。本記事では、このVLAについて紹介します。
VLAとは?
Vision-Language-Action Models(VLA)は、視覚、言語、そして行動の3つのモダリティからの情報を統合的に処理するマルチモーダルモデルです。これは、テキストベースの対話を行うChatGPTのような会話型AIとは異なり、環境とインタラクションする物理的な実体(ロボットなど)を制御することを目的としています。特に、言語による指示に基づいてロボットがタスクを実行する「言語条件付きロボットタスク」において、VLAは言語の理解、環境の視覚的認識、そして適切な行動の生成という不可欠な能力を発揮します。
例えば、VLAを統合したロボットはユーザーからの「ボトルをとって」(Language)という指示が与えられると、カメラ画像(Vision)を元に環境(例:ボトルの形状や位置)を把握し、ボトルを掴むための行動(Action)を生成することができます。
VLAという用語は比較的新しく、文献[2]によると「VLA」の語が提唱されたのはA. Brohanらの論文『RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control』[1]であると記述されています。(ただし視覚・言語・行動を統合するアプローチ自体はそれ以前の研究にも見られます)
VLAは複雑な環境において、汎用性、器用さを提供すると期待されています。これにより、工場のような制御された環境だけでなく、私たちの日常生活における様々なタスクへの応用も視野に入ってきています。
VLAの基本的な構成要素
VLAの一般的なアーキテクチャはY. Maらの論文『A Survey on Vision-Language-Action Models for Embodied AI』[2]では下記のように図示されています。
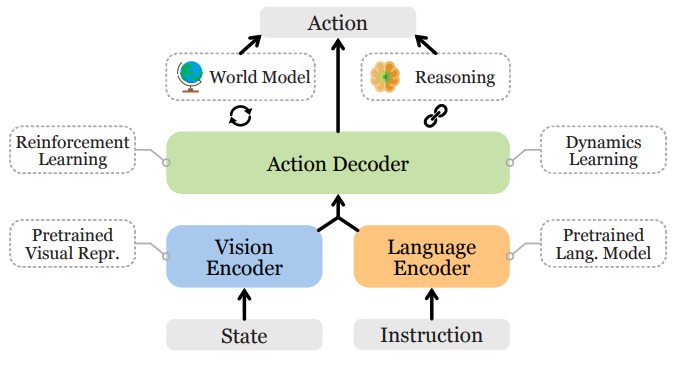
主要な構成要素は以下の通りです。
- Vision Encoder
環境の視覚情報を処理し、特徴量を抽出する役割を担っています。現在の環境状態(物体のクラス、姿勢、形状など)に関する事前学習された視覚的表現を取得するためにビジョン基盤モデルなどを用いてエンコードされます。
- Language Encoder
ユーザーの指示やタスクの説明といった言語情報を処理し、意味的な埋め込み(embedding)を生成する役割を担っています。近年ではLarge Language Models(LLMs)がLanguage Encoderとして広く利用されています。
- 視覚と言語の埋め込みの整列
Vision EncoderとLanguage Encoderによって得られた視覚情報と言語情報の埋め込みを効果的に関連付けるための様々な戦略が用いられます。
- Action Decoder
整列された視覚と言語の情報を基に、言語条件付きロボットタスクを実行するための適切な行動を予測します。近年では、この行動デコーダにTransformerベースのアーキテクチャを採用する研究が増えています。
Vision EncoderとLanguage EncoderとしてVLMのアーキテクチャや事前学習済み表現が活用されることがあります。VLMはインターネット上の膨大なテキストと画像のデータで、視覚情報と言語情報の対応付けを行うように事前学習されているため、学習データに明示的に含まれていなかった新しい物体や概念についても関連する言語情報を手がかりに認識することができます。これによりVLAは言語による指示と視覚的な理解に基づいて、多様な環境やタスクに対応できる汎用性と実用性を高めることができます。
VLAのモデル
下記ではVLAモデルを幾つか紹介します。
RT-1[3]
RT-1はGoogle Deepmindにより2022年12月に発表されました。Transformerをベースとしたモデルであり、ロボットのカメラで取得した画像と自然言語の指示を入力とします。出力は下記の離散化された行動空間に属するトークンです。
- モードの切り替え(1次元)
アーム制御するのか、台車などのベースを制御するのか、エピソード終了を表すのか?
- アームの動き(7次元)
x, y, z座標やグリッパーの開閉など
- 台車の動き(3次元)
x, y座標や回転の情報
RT-1は最大6枚の画像履歴を受け取るとImageNetで事前学習されたEfficientNet-B3を通して処理します。最終的な畳み込み層から9 × 9 × 512の空間特徴マップが出力され、81個のビジョン・トークンに平坦化されます。
自然言語命令はまず、Universal Sentence Encoder(USE)によって埋め込みベクトルに変換されます。この言語埋め込みは、FiLM(Feature-wise Linear Modulation)層を、事前学習済みEfficientNetの内部に挿入することで、画像エンコーダーを条件付けます。これによりタスクに関連する画像特徴が抽出されます。抽出された視覚、言語の特徴量はTokenLearnerによりトークン化されます。この時、少ない数のトークン(論文中では画像あたり8個)にマッピングすることにより重要なトークンのみを後続のTransformerに渡します。Transformerバックボーンには合計で48個のトークン(6枚の画像履歴 × 8トークン)が入力されます。
このような効率的なアーキテクチャーを採用することで3Hzでの実時間制御を可能としました。
RT-2[1]
RT-2はGoogle DeepMindにより2023年に発表されました。RT-2はインターネット規模のデータで学習された大規模なVision-Language Model(VLM)を基盤としています。
RT-2の大きな特徴は、ロボットの行動をテキストトークンとして表現することであり、VLMが持つ豊富な知識をロボット制御に直接転移させることを可能にします。このモデルは、VQA(Vision Question Answering)データなどのWebスケールのデータと、ロボットの軌道データを元にco-fine-tuning(マルチモーダルデータを同時にファインチューニングする戦略)されており、その結果優れた汎化能力や簡単な推論能力を獲得しています。
RT-2は、RT-1で提案された離散化された行動空間のアイデアを継承しており、連続的な行動次元を離散的なテキストトークンとして出力します。RT-2は、PaLI-XやPaLM-Eといった大規模なVLMを基盤としており、インターネット規模の事前学習済み知識をロボット制御に活用するという点で、RT-1とは大きく異なります。
π0[4]
π0はPhysical Intelligence社より2024年10月末にπ0のテクニカルレポートとデモ動画が発表されました。π0はインターネット規模の知識を取り込むためにVLM PaliGemmaを事前学習モデルとして用いています。また、VLMの基盤に加えて連続的な行動分布を生成するためにconditional flow matchingをベースとした方策モデルを組み合わせています。
モデルは多様なロボット構成やタスクで収集されたデータとOXE(Open-X Embodiment)データセットを含む大規模な事前学習データで訓練され、広範な能力と汎化性を獲得しています。RT-2がロボットのアクションを離散的な行動空間として表現するのに対して、π0はflow matchingを用いて連続的なアクション分布をモデル化しています。これにより、高精度で複雑な行動のモデリングが可能になります。
実際Physical Intelligence社はπ0を用いて洗濯物の折りたたみやテーブルの片付けといった複雑で連続的な動作を実現するデモ動画を公開しています。
VLAのユースケース
VLAは、視覚情報と言語指示を統合し、物理世界で具体的な行動を生成する能力を持つため、多岐にわたる分野での応用が期待されています。VLAの活用が期待されるユースケースについて紹介します。
ただし、VLAの汎化性能やタスクの実行精度はまだまだ実用において課題があります。下記で紹介するのはあくまで将来的に期待するユースケースと認識ください。
産業応用
工場や倉庫などの産業分野においてVLAは効率化や自動化に大きく貢献する可能性があります。
- 柔軟な生産ライン
-
言語による指示や製品の視覚的な特徴に基づいて、ロボットが様々な組み立て作業やピッキング作業を柔軟に行うことができます。従来の固定されたプログラムによる自動化と比較して、VLAは多様な製品やタスクへの迅速な対応が可能になり、またセットアップコストの削減も期待されます。
環境の変化(例:作業机のテーブルクロスの柄の変化)に対しても柔軟に対応できる可能性があります。
- 物流・倉庫管理
言語指示に基づいて、倉庫内の物品の探索、ピッキング、梱包、運搬などをロボットが行うことで、効率性と省人化を実現できます。
日常生活支援
VLAは私たちの日常生活における様々なタスクを支援する可能性を秘めています。特に、人間と自然な形でインタラクションしながらタスクを実行できる点が期待されています。
- 家事の自動化
言語による指示(例:「テーブルの上の皿を片付けて」「洗濯物を畳んで」)に基づき、ロボットが環境を視覚的に認識し、適切な行動を実行することで、家事の負担を軽減できます。
- インタラクティブなアシスタント
人間の問いかけ(例:「リモコンを持ってきて」など)に対し、インタラクティブにロボットを制御することで、人間のアシストを行います。例えば、「少し寒いからブランケットを持ってきてくれる?」といった曖昧な要求に対しても、VLAは状況を理解し、適切な行動を取ることが期待されます。
VLAの課題や今後の展望
VLAの活用が進むには多くの課題があります。
例えば安全性です。ロボットが人間と安全に協調して作業するためには安全機構を確立する必要があります。また、基盤モデルとその汎化性能の発展も課題です。一般的にロボットのアクションを記録したデータは自然言語のようなデータと比べて少なく、ロボットデータをいかに大規模に収集して学習させるかということは検討が必要です。
一方で、上述したようにVLAが視覚・言語・行動を統合することでロボットがより賢く、より柔軟に人間と共存するための重要な技術となる可能性を秘めています。今後の研究開発の進展により、VLAが私たちの生活にどのように変革をもたらすのか非常に興味深いです。
VLAやACCESSの製品にご興味がありましたら、お問い合わせよりお気軽にご連絡ください。
参考文献
- [1] A. Brohanら『RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control』(arXiv:2307.15818)
- [2] Y. Maら『A Survey on Vision-Language-Action Models for Embodied AI』(arXiv:2405.14093)
- [3] A. Brohanら『RT-1: ROBOTICS TRANSFORMER FOR REAL-WORLD CONTROL AT SCALE』(arXiv:2212.06817)
- [4] K. Blackら『π0: A Vision-Language-Action Flow Model for General Robot Control』(arXiv:2410.24164)