近年、AIが持つ高度な知能をロボット制御へと拡張するEmbodied AI(身体性AI)が急速に活発化しています。このようなAIモデルは「Vision-Language-Action(VLA)モデル」と呼ばれるものが主流です。VLAモデルの登場により汎用ロボットの実現が現実味を帯びる一方で、AIに「自分の行動によって世界(環境や物体)が次にどう変化するか」を予期させるのが困難であるという、次なる課題も浮き彫りになってきています。
本記事ではそのような課題に対し、VLAとは異なるアプローチとして現在注目を集めている「World Action Model(WAM)」を紹介します。
VLAの課題
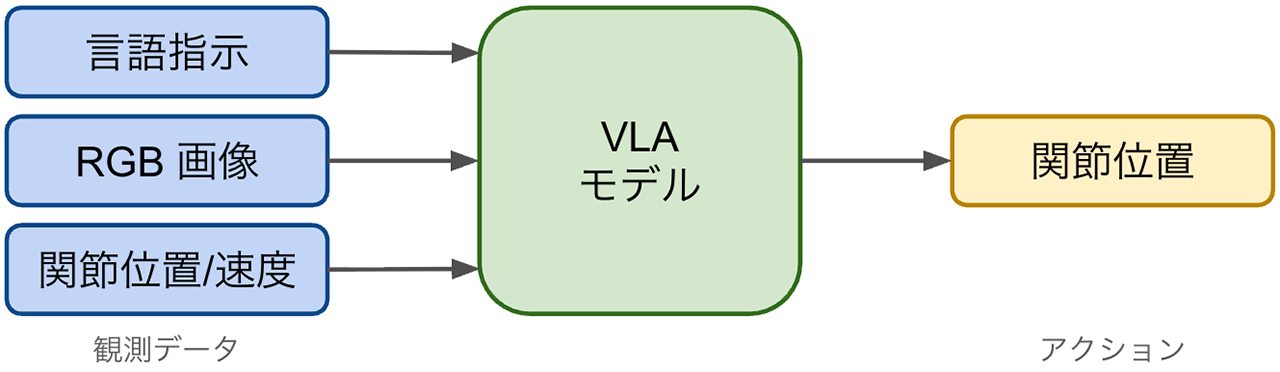
まずは冒頭でも触れたVLAモデルが抱える課題について説明します。
VLAモデルとは、自然言語のタスク指示〔Language〕と、ロボットに取り付けられたカメラなどの画像〔Vision〕やロボットの現在の状態を入力として、自然言語のタスク指示を満たすためのロボットの行動〔Action〕を直接生成することができるモデルです。π0を始めとするVLAモデルの主流となっているアーキテクチャでは、画像や言語の処理として大規模な視覚および言語データで学習された基盤モデル(VLM、Vision-Language Model)をバックボーンに採用しています。これにより、VLAモデルは言語による指示と視覚的な理解に基づいて、多様な環境やタスクに対応できる汎用性と実用性を高めることが期待されています。(VLAやVLMについては「Vision-Language-Action (VLA) Modelとは?」でも詳しく紹介しています)
VLAモデルは上記のような特徴や期待がある一方で、実際には限られた汎化能力や、外乱や乱雑な環境に対するロバスト性の欠如など、いくつかの課題も指摘されています。原因の1つとして、多くのVLAは主として画像・言語中心に事前学習されたVLMを基盤としており、現実世界におけるダイナミクス(時間とともに物事がどう変化するか、その動きや仕組み)の理解には制約があることが考えられます。その結果、VLAモデルはタスクや環境に特化した行動データを大規模に収集しなければ、新しい環境やタスクへの汎化に苦戦することがよくあります。
World Action Model(WAM)とは
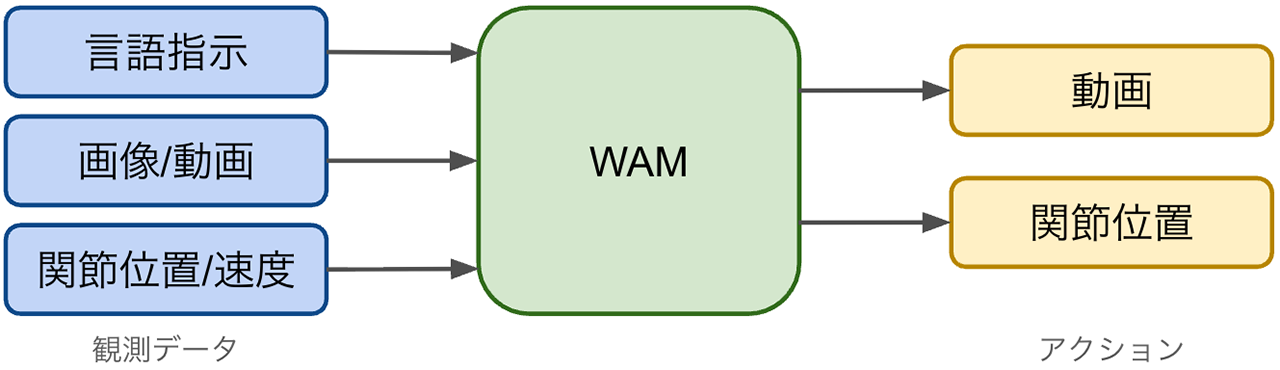
VLAとは異なるアプローチとして、主に動画生成モデルを活用する「World Action Model(WAM)」というアプローチが現在注目を集めています。World Action Modelという語句自体はSeonghyeon Yeらの論文[1]『World Action Models are Zero-shot Policies』(以降、DreamZero論文と呼称)で提唱され、WAMとは「行動と視覚的な未来の状態の両方を、整合性のある方法で予測するように設計された基盤モデル」であると紹介されています。
先述したように多くのVLAは画像・言語中心に学習されたVLMをバックボーンとして利用しているため、環境の時間的変化や未知の動作への適応に限界がありました。しかしWAMではWeb上の膨大な動画データから得られた動画生成モデルを利用することで、(動画生成モデルが持っていると期待される)時間とともに物事がどのように動き変化するかという時間的・空間的な変化パターンへの理解を活用し、行動と視覚的な未来の状態の予測を行います。このような仕組みにより、WAMには、学習データに存在しなかった初見タスク・未知の環境へのゼロショット汎化能力や、ノイズ・照明変化・背景パターンの変化・無関係な障害物の配置といった様々な視覚的・環境的な外乱に対するロバスト性の向上が期待されています。
実際にMoo Jin Kimらの論文[2]『Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning』で提案された「Cosmos Policy」と呼ばれるWAMは、少量の学習データでありながらも、一部のベンチマークの総合スコアにおいてオープンなVLAモデルとしては現時点で最先端のモデルの1つであるπ0.5*1を上回る性能を見せました。さらにDreamZero論文で提案されたWAMでは、未知のタスクや環境へのゼロショット汎化の実験において、VLAの平均2倍以上の成功(タスク進行度)を示しました。
*1 π0.5の開発元であるPhysical Intelligence社は、π0.5の公開の後に、より性能が高いπ0.6やπ0.7といったVLAモデルを発表しています。ただし現時点でこれらはモデルがオープンになっていないため、現時点の最先端VLAとの公平な性能比較は難しいことに注意が必要です。
WAMに関する研究
Bohan Houらの論文[3]『World Model for Robot Learning: A Comprehensive Survey』では、World Model(世界モデル)をロボットの行動決定(ロボットポリシー)に組み込む研究についてまとめられており、主要な研究の発展の流れを下図のように紹介しています。
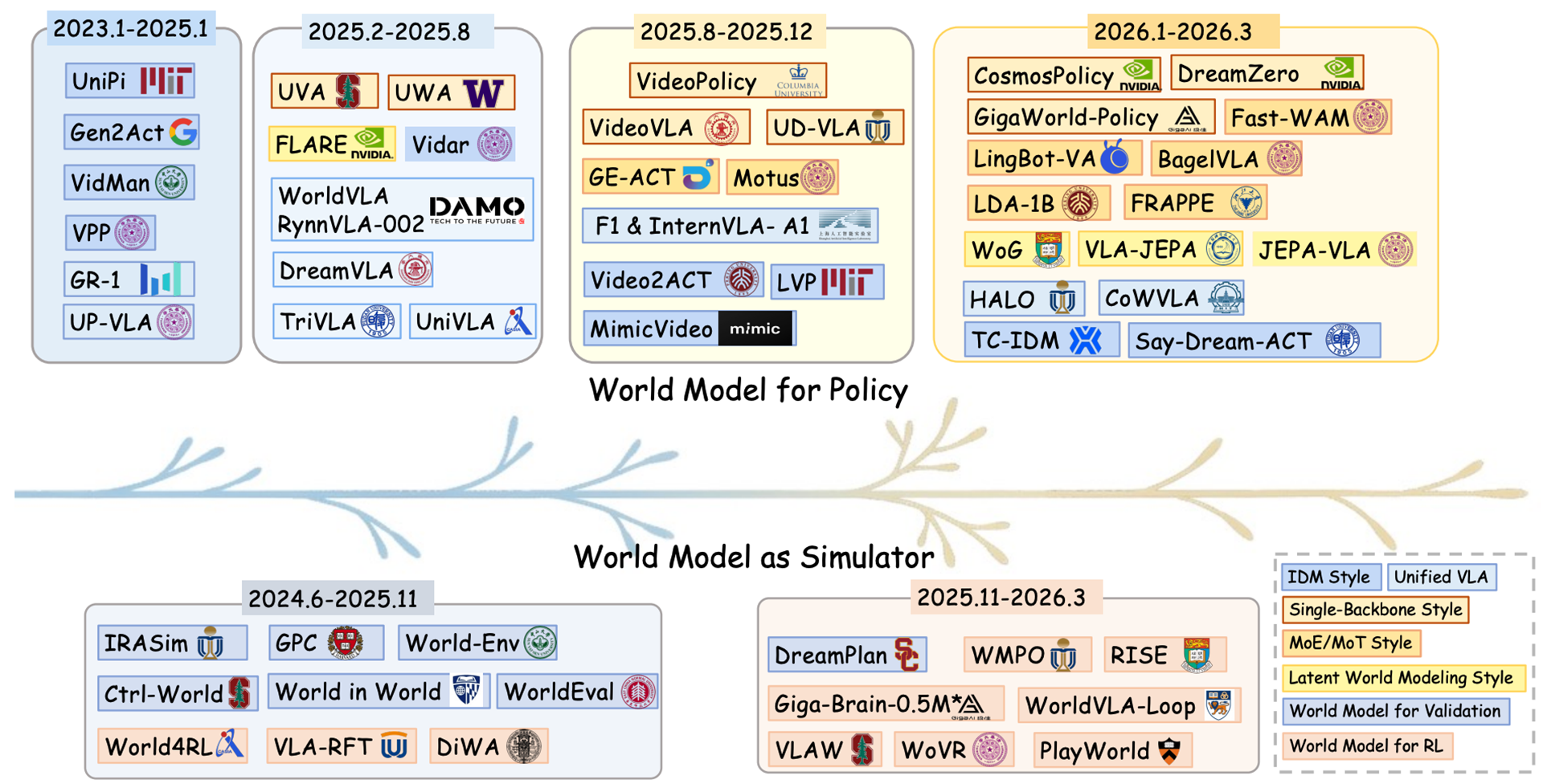
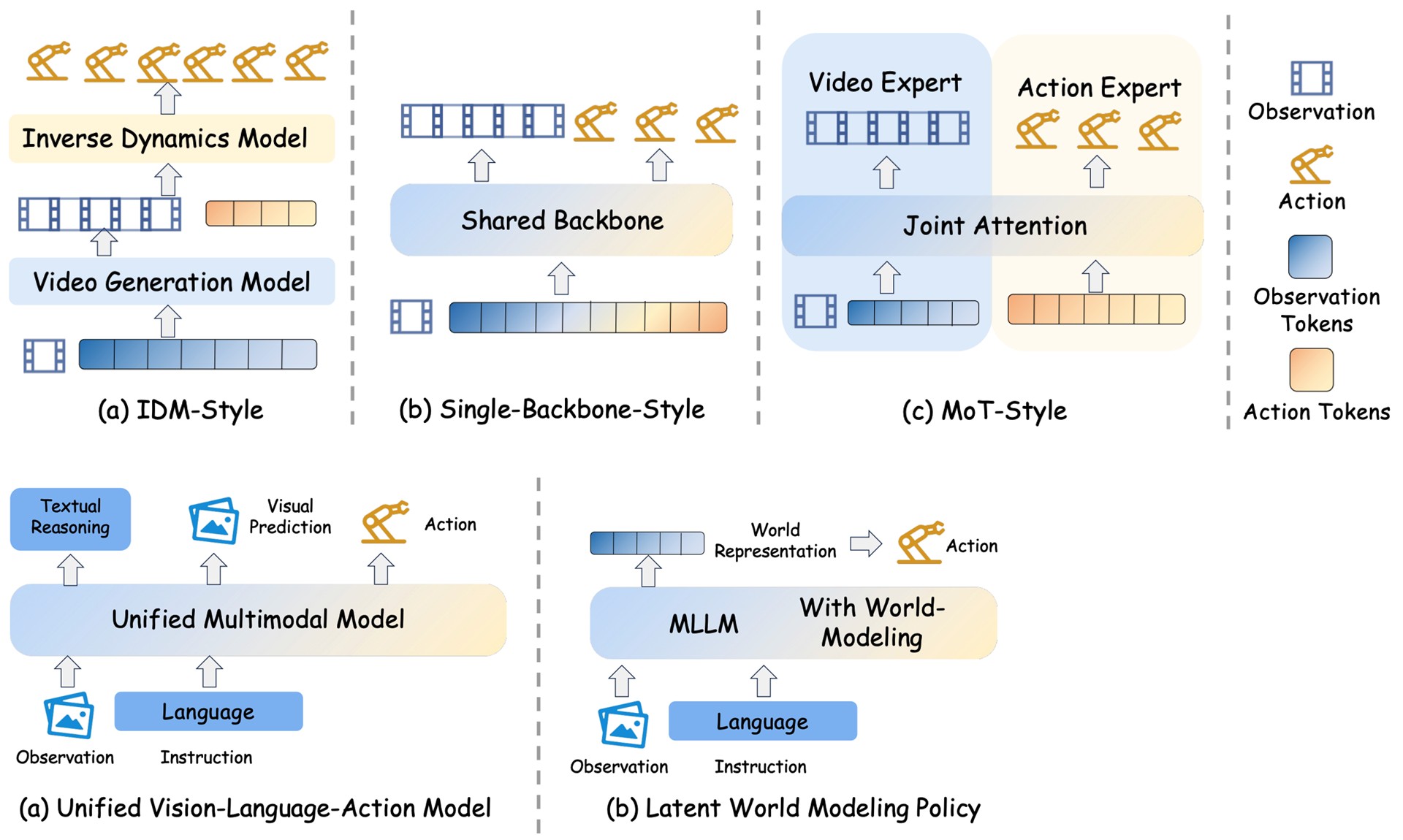
また、この論文ではWorld Modelをロボットポリシーへ組み込むアーキテクチャを、大きく5つに分類しています。
- IDM-style
映像予測と行動生成を完全に切り離したアプローチです。動画生成モデルが未来の映像を生成し、別の逆動力学モデルがそれを行動に変換します。
- Single-backbone-style
映像予測と行動生成を一つの同じネットワーク内で処理し、未来予測と行動生成を統合的に行います。
- MoT-style
映像予測と行動生成のネットワークを分離したまま維持します。ただしIDM-styleと異なり、アテンション機構などを通じて深く相互作用させます。
- Unified Vision-Language-Action Models
VLAモデルの内部に未来予測の仕組みを直接組み込むアプローチです。行動と同時に未来の画像を予測・生成するモデル(GR-1など)や、圧縮された世界知識を暗黙的に予測するモデルなどが含まれます。
- Policies with Latent-Space World Modeling
明示的な画像や動画の生成に依存することなく、AIの内部の潜在空間において未来の変化を予測し、行動決定に活用するアプローチです。
次項では、IDM-styleのモデルである「Video Prediction Policy(VPP)」と「mimic-video」、Single-backbone-styleのモデルである「Cosmos Policy」と「DreamZero」について、より詳しく紹介します。
IDM-styleの研究
Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations
Yucheng Huらによって2024年12月に発表された論文[4]です。
WAMの先駆けとも言える「動画生成モデルの時系列予測能力をロボット制御へ活用する」手法を提案した研究の1つです。この論文で提案されたVideo Prediction Policy(VPP)モデルでは、まず動画生成モデルに「テキストの指示に従って未来の映像を予測する」タスクを事前学習させます。そしてその動画生成モデルが生成した未来の視覚的な特徴をもとに、別のポリシーネットワークがロボットの行動を生成します。この論文では、学習データに含まれない新しい物体や背景シーンなど、学習分布外の操作・環境に対しても高い汎化性能を発揮しベースラインより高い成功率が示されました。
一方で、映像予測と行動予測が別々のネットワークとして切り離されているため、単純に組み合わせただけでは「予測された未来の映像」と「ロボットが実際に実行する行動」の間にズレが生じやすいという課題を残しています。
mimic-video: Video-Action Models for Generalizable Robot Control Beyond VLAs
Jonas Paiらによって2025年12月に発表された論文[5]です。
この論文で提案されたmimic-videoモデルは、以下の2つのFlow Matchingベースのモデルを組み合わせて構築されます。
- 動画生成モデル(Cosmos-Predict2等)
過去の画像と自然言語の指示から、ロボットがタスクを達成するための「未来の映像」を潜在空間で予測します。
- アクションデコーダ
動画生成モデルが思い描いた「未来の映像」を受け取り、それをロボットの実際のモーター制御コマンドに変換する逆動力学モデルとして機能します。
mimic-videoも、映像予測と行動予測が別々のネットワークとして切り離されている点はVPPと共通しています。しかしmimic-videoでは未来の動画を最後まで生成させず、あえてノイズが残った未完成な潜在状態に留めたうえで、それを用いてアクションデコーダを条件付けしている点に特徴があります。
この特徴により下記の利点をもたらします。
- 分布シフトの緩和
-
推論時に動画生成モデルが最後までノイズを除去して生成した綺麗な映像は、動画生成モデル自身の能力の限界ゆえに間違った未来の映像を描写してしまう可能性があります。仮に正確な映像だったとしても、実際の正解データとは微妙に異なる映像になってしまう傾向があります。
そこで意図的に視覚的プランにノイズを残すことで、訓練データ(綺麗な正解映像)にしか存在しないような見せかけの視覚的な手がかりにアクションデコーダが過剰に依存してしまうのを防ぎ、結果としてモデルのロバスト性を向上させます。
- 推論時間の短縮
計算コストが極めて高い完全な動画生成プロセスをスキップできるため、推論時間を短縮できます。
また、モデルの学習においても、複雑で長期的な未来予測をすべて動画生成モデルに任せ、ロボットの行動を生成するアクションデコーダの役割を完全に切り離して学習させています。これによりアクションデコーダの役割を、動画生成モデルが提示した「未来の映像」を「実際のロボットの制御コマンド」に変換するだけの単純なタスクとすることができます。結果、アクションデコーダはこの単純なタスクに全能力を集中できるようになり、非常に少ないロボットデータでも素早く学習できるようになりました。論文中の実験では、同等性能のVLAモデルと比較してサンプル効率を10倍に向上させ(つまり10分の1のロボットデータで同等の性能を達成)、収束速度を2倍に高速化できたことを示しています。
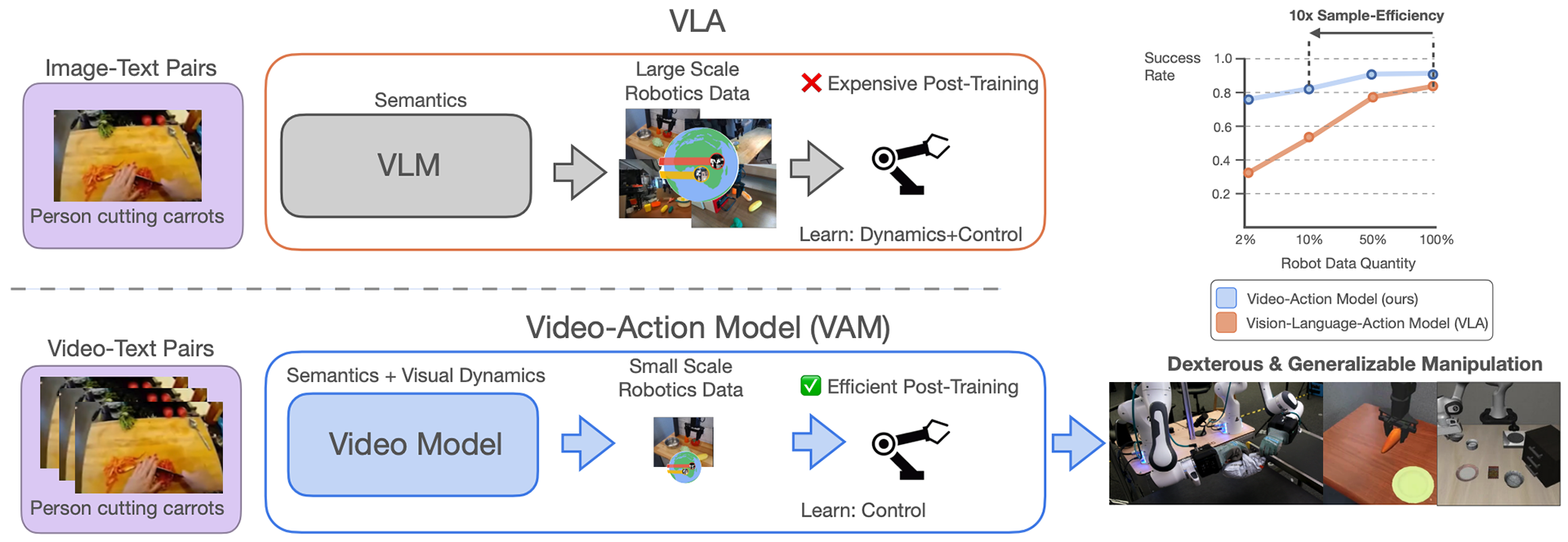
さらに、オクルージョン(手や物体が重なって見えなくなる状態)が多い複雑なタスクでも高い成功率を示しており、動画生成モデル由来の時系列表現がオクルージョン下で有効に機能した可能性が示されています。ただ一方で、大規模なクロスエンボディメント(異種ロボット間転移)モデルの実現には至っておらず、動画生成モデルに期待される汎化能力が完全には引き出されていないことが課題として挙げられています。
なお、この論文では上記のような映像予測と行動生成を統合したモデルを表す用語として、WAMではなく「Video-Action Model(VAM)」という語句を提唱しています。
Single-backbone-styleの研究
Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
Moo Jin Kimらによって2026年1月に発表された論文[2]です。
強力な動画生成モデル(Cosmos-Predict2-2B)をベースにしたモデルであるCosmos-Policyを提案しています。
上記で述べたように、IDM-styleの手法は映像予測と行動予測が別々のネットワークとして切り離されている構造となっており、複数段階の学習が必要でした。また、ネットワークが切り離されていることにより「モデルが予測した未来の映像と、実際に出力される行動の間にズレ(アライメントの不一致)が生じやすい」という課題もあります。例えば、VPPでは動画生成モデルを利用して一度に固定のフレーム数を予測・生成する仕組みになっています。しかし固定長のフレームを生成する場合、タスクが長くなるとそれを固定長のフレームに収めるためには動画のフレームを間引く必要が出てきます。これをすると動画の再生速度(FPS)が本来の現実の速度から歪んでしまいます。
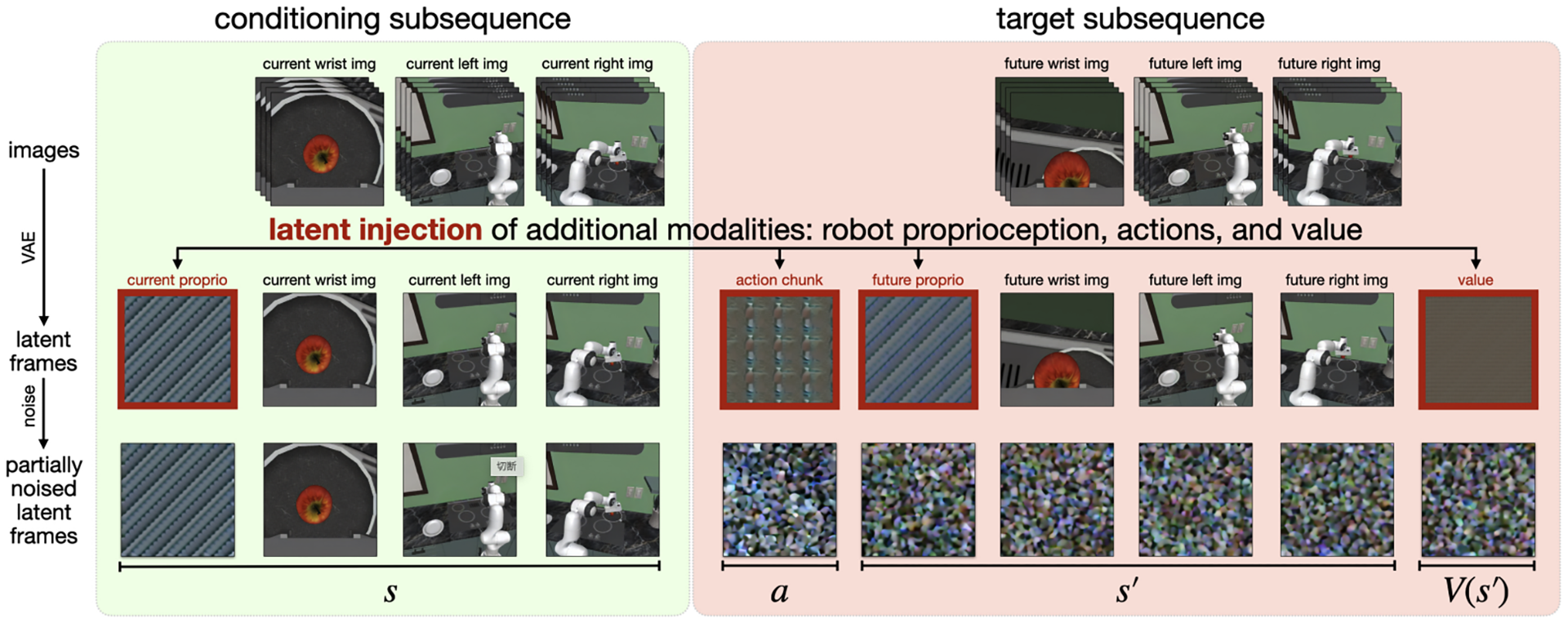
一方でCosmos-Policyは、動画生成モデルの主要構造を大きく変更せず、そのままロボット制御に応用した研究です。Cosmos-Policyの最大の工夫は「Latent Injection」と呼ばれる手法です。本来、動画生成モデルは映像系列のみを扱うモデルですが、そこに下記のロボット固有の情報(State/Action Chunk/Value)を、画像と同じサイズの「latent frame」というデータ形式に変換し動画のフレームとフレームの間に挿入しました。
- State
ロボットの現在の関節の角度など
- Action Chunk
ロボットの行動
- Value
その行動をとったらどれくらいタスク成功に近づくかという期待値
これにより、元の動画生成モデルのアーキテクチャを大きく変更せずに、1つの拡散プロセスの中で「未来の映像」「ロボットの行動」「タスクの価値」の3つを同時に生成・予測できるようになりました。
結果としてCosmos-Policyは、単腕ロボットのベンチマークであるLIBEROで平均98.5%、RoboCasaで67.1%という最高性能を記録し、π0・π0.5・OpenVLAなどの強力なVLAを上回りました。実世界のALOHAロボットを用いた実験でも、細かい精度が求められる難しいタスク(キャンディーをジッパー付き袋に入れる等)において、π0.5などが失敗しやすい状況でも安定して動作し、最高の平均スコア(93.6%)を達成しています。
一方で、推論速度の遅さが課題として報告されています。行動だけを出力する場合は約0.6〜0.95秒で済みますが、プランニング(未来の映像と価値を複数予測し、最適な行動を探す処理)を行うと、行動の決定に約4.9秒もかかってしまいます。この推論速度の遅さが、リアルタイムの対応が必要な動的タスクへの応用の壁になっており、速度向上が今後の重要な研究方向であると述べられています。
World Action Models are Zero-shot Policies
Seonghyeon Yeらによって2026年2月に発表された論文[1]です。
この論文では、14Bのパラメータを持つ事前学習済みの動画生成モデル(Wan2.1-I2V-14B-480P)をベースに構築されたモデルであるDreamZeroを提案しています。また先述したように、この論文では「行動と視覚的な未来の状態の両方を、整合性のある方法で予測するように設計された基盤モデル」という概念に対して「World Action Model(WAM)」という名称を与えることが提唱されました。mimic-video論文で提唱されたVAMではなくWAMという語句を提唱・採用した理由は、この論文の著者たちは「動画(Video)による予測は世界モデリングのための1つの手段に過ぎない」と考えたためです。
DreamZeroもCosmos Policyと同様に、「未来の映像」と「ロボットの行動」を1つのモデルで同時に予測します。しかしベースモデルのアーキテクチャを大きく変更していないCosmos Policyと異なり、DreamZeroでは状態エンコーダや行動のエンコーダ・デコーダを追加するなど、アーキテクチャ上の工夫を行っています。
DreamZeroの特徴
- 自己回帰型アーキテクチャの採用
-
DreamZeroでは、過去の映像コンテキストを参照しながら自己回帰的に予測を行うアーキテクチャを採用しました。これは短いチャンクごとに過去の映像を参照しながら、次々と未来を予測していく方式です。
これによりDreamZeroは任意の長さのタスクに対応でき、VPPで発生したような固定長に収めるためにフレームを間引く必要がなくなり、現実の本来のフレームレートを保ったまま「言語・映像・行動」を同期させることが可能になりました。
- KVキャッシュによる高速化とその更新
-
過去の計算結果を「KVキャッシュ」として保存・再利用することで、動画と行動のチャンクを同時に高速で処理します。さらにロボットが行動を実行するたび、KVキャッシュ内の「予測した映像」をカメラからの「現実の映像」に置き換えます。
これにより動画生成モデル特有の予測のズレが雪だるま式に蓄積する問題に対処しました。
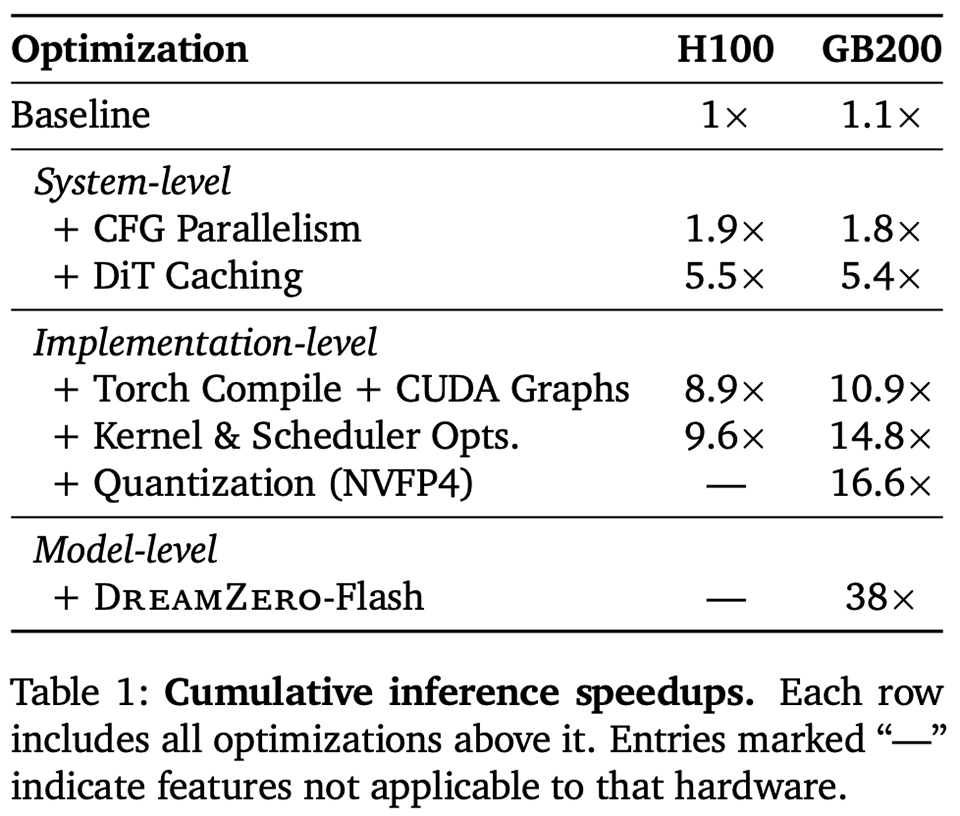
また、DreamZeroはGPUベンダーであるNVIDIA社から発表されたモデルということもあり、システム・実装・モデルと広範なレイヤーにまたがって下記の最適化が行われました。
システムレベルの最適化
- Classifier-free guidance(CFG)処理の並列化
拡散モデルの計算ではClassifier-free guidance(CFG)という手法が使われていますが、CFGに必要な条件付き・無条件推論を並列実行することで推論レイテンシを削減しました。
- DiTキャッシング
Flow Matchingの計算では速度ベクトルを予測しますが、この予測される速度ベクトルには、連続するステップ間で方向が一定に保たれやすいという性質があります。この性質を利用して、連続するステップ間の類似度が事前に設定した閾値を超えた(つまり変化の方向が前回とほぼ同じである)場合、重いDiTの計算をスキップし、キャッシュしておいた前回の速度ベクトルを再利用するようにしました。
実装レベルの最適化
- Torch CompileとCUDA Graphsによるオーバーヘッドの排除
巨大なモデルを動かす際、GPU自体の計算速度よりもCPU側の処理がボトルネックになっていました。このCPUのオーバーヘッドを根本から排除するために、PyTorchの機能であるTorch CompileとCUDA Graphsを組み合わせて使用しました。
- カーネルの最適化
PyTorch 2.9以上の機能であるcuDNNバックエンドを利用することで、AttentionのScaled Dot-Product Attention(SDPA)演算を高速化しました。
- スケジューラの最適化
-
DreamZeroが推論時に使用する「Flow UniPCスケジューラ」の初期実装では、いくつかの演算をCPU上で行う必要がありました。しかし、これによってCPUとGPUの間で頻繁な同期が発生し、GPUのストール(処理待ち)を引き起こしていました。
これを解決するため、スケジューラの計算処理をGPU側に移行させました。これにより不必要なCPUのオーバーヘッドと同期の待ち時間が完全に排除され、スムーズで高速な推論が可能になりました。
- 量子化
精度が必要な演算(QKV、Softmax)はFP8に、非線形演算はFP16に保ちながら、重みとアクティベーションにはBlackwell GPUでハードウェア的にサポートされたNVFP4を採用しました。
モデルレベルの最適化
- DreamZero-Flash
学習時に「ノイズが多く不完全な動画」から行動を予測させるようにしました。これにより、推論時に動画のノイズ除去計算(ステップ数)を4回から1回に減らしても、正確な行動を出力できるようになりました。
結果として、処理時間を5.7秒から150ミリ秒へと38倍高速化し、巨大な14Bモデルでありながら実用的なリアルタイム制御の閾値に迫る7Hzを実現しました。
各処理における高速化の結果は下記の表に示されています。
DreamZeroは、VLAモデル(GR00T N1.6など)と比較した実機テストにおいても高い性能を示しています。
- 未知のタスク・環境へのゼロショット汎化
「靴紐を解く」「アイロンがけ」「握手をする」といった、事前学習にまったく含まれていない初見のタスクにおいて、VLAのベースラインに対して平均2倍以上の成功(タスク進行度)を示しました。
- 動画データからのクロス・エンボディメント転移
別のロボットや人間の一人称視点の動画をわずか10〜20分間追加学習するだけで、未知のタスクへのタスク進行度が相対的に42%以上も向上しました。
- 30分での新しい体への適応
AgiBotというロボットで学習したモデルを、別の新しいロボット(YAM)に移植する際、わずか30分間のプレイデータだけで適応し、初見の物体も適切に操作できる能力を維持しました。
まとめ
ロボットポリシーに組み込むAIモデルとしては、現在はVLMをバックボーンにしたVLAが主流ではありますが、WAMもVLAに対して性能面で追いつき始めています。また、VLAの学習に使われるデータはLLMなどに使われるものと比べると数が少なく、学習データの作成も大きなコストがかかることが課題になっています。しかしながらWAMの場合は大量のロボットデータを集めるのではなく、替わりにWeb上に無数に存在する人間の主観視点ビデオから時間的変化パターンを学習し、ロボットの未知のタスクへの転移能力をさらに引き上げることが期待されており、学習データの少なさへの対処としても期待が持てます。
一方で、WAMは推論時間が長くなりがちといった問題点もあります。例えばZhanguang Zhangらの論文[6]『Do World Action Models Generalize Better than VLAs? A Robustness Study』では、論文中で比較したWAMはπ0.5と比べ、少なくとも4.8倍以上の推論時間となっていると記述されています。ロボットは現実空間で動きますが、様々な物理現象はモデルが推論している時間を待ってくれるわけではありません。そのため推論時間が長いという点は解決すべき重要な課題といえます。
しかしながらWAMもVLAも盛んに研究が行われており、日に日に新たなアーキテクチャや手法が提案され、非常に可能性を感じさせてくれる技術であることは違いありません。WAMやVLA、弊社製品にご興味がありましたら、お問い合わせよりお気軽にご連絡ください。
参考文献
- [1] Seonghyeon Yeら『World Action Models are Zero-shot Policies』(arXiv:2602.15922)
- [2] Moo Jin Kimら『Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning』(arXiv:2601.16163)
- [3] Bohan Houら『World Model for Robot Learning: A Comprehensive Survey』(arXiv:2605.00080)
- [4] Yucheng Huら『Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations』(arXiv:2412.14803)
- [5] Jonas Paiら『mimic-video: Video-Action Models for Generalizable Robot Control Beyond VLAs』(arXiv:2512.15692)
- [6] Zhanguang Zhangら『Do World Action Models Generalize Better than VLAs? A Robustness Study』(arXiv:2603.22078)