力情報を扱うVLAモデルのサーベイ
「Vision-Language-Action (VLA) Modelとは?」では、VLAモデルの基本構成や代表的なモデルを紹介しました。VLAは多くのタスクで成果を上げていますが、接触を多く伴うタスクではまだ課題が残っており、力情報をモーダルとして追加することで改善を図る研究が増えています。
本稿では、力情報を扱うVLAモデル(本稿ではVision-Tactile-Language-Action Model〔VTLAモデル〕と総称)に関する8件の文献を、力のセンシング・モデルの拡張方法・制御方式の3つの観点から整理します。
VLAモデル/VTLAモデルとは?

VTLAモデルとは、VLAモデルに対して入力や出力に「力情報(Tactile)」を追加したものと定義*1でき、食品などの柔らかい物体を扱うために効果的なモデルです。
- VLAモデル
視覚・言語・関節状態を入力し、関節位置を出力するマルチモーダル模倣学習モデル。
- VTLAモデル
VLAモデルの入力や出力にトルク・触覚画像などの力情報(図の赤字の箇所)が追加されたモデル。
*1 ACTのようなVAモデル(言語なし)の拡張も含めて本稿では「VTLA」と総称します
なぜ力情報が必要か?
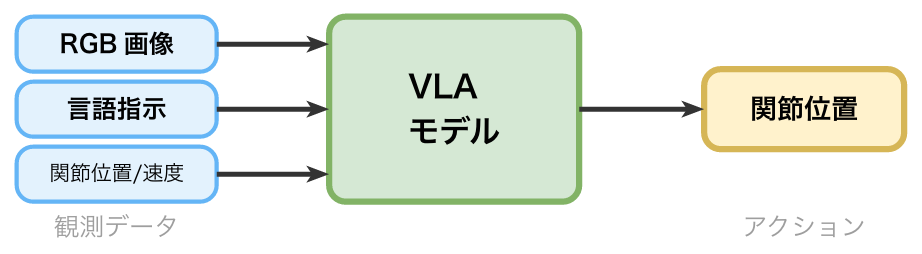
従来のVLAモデル
従来の模倣学習ベースのVLAモデルは視覚・位置情報のみでタスクを実行しており、以下の課題を抱えています。
- データ収集時
-
位置制御のみの遠隔操作では操作者に接触の感覚が伝わらず、力を使わないデモ動作になりやすい[8]
遠隔操作は非効率
ズッキーニの皮むきでは、完了時間が手作業*2では5分以内なのに対して遠隔操作では13分以内[10]
*2 ForceMimicが提案するロボット不要の直接デモ収集方式。人間がツールを持ち、力データを直接記録する
- 観測データ(モデルへの入力)
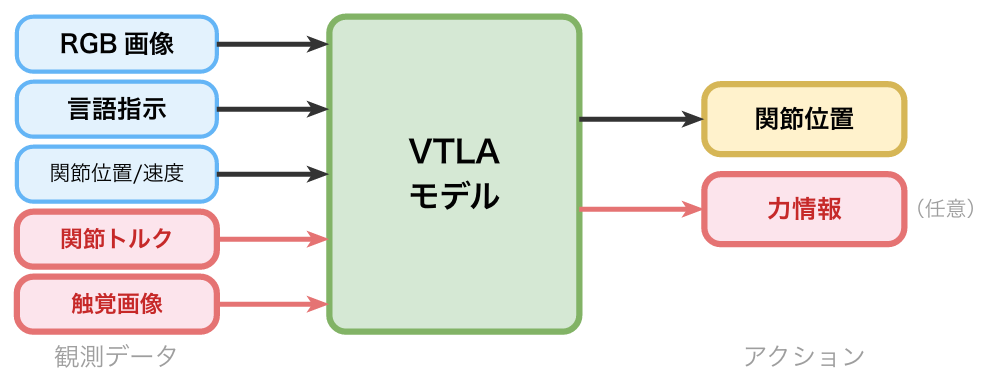
VTLAモデルでの改善
VTLAモデルに関する文献では、これらの課題に対して以下のような改善が報告されています。
- データ収集時
-
バイラテラル制御(力の双方向伝達)で、リーダーの操作者がフォロワーの触覚をフィードバックにより感じながら動作を収集できる
- 観測データ(モデルへの入力)
-
視覚だけではわからない物体特性の情報が得られます。
関連文献の分類
関連文献は、力のセンシング・VLAモデルの力拡張方法・制御方式の観点で以下のように分別できます。
- 力センシング
-
- 関節トルク(内部推定)
- 触覚画像(外部・2D画像取得)
- トルクセンサ(外部・値取得)
- 力の入力方法
-
- VLM側(Enc有/無)
- AE側(MoE:混合エキスパート)
- AE側(MLP:多層パーセプトロン)
- 直接結合
- 制御方法
-
- 位置出力 → 位置制御
- 位置+力出力 → 力補正付き
- 位置+力出力 → ハイブリッド
| 研究 | カメラ | 力センシング | ベース | 力の入力方法 | 出力 | 制御 |
|---|---|---|---|---|---|---|
| ForceVLA[1] | RGB×2 | 内蔵推定値(6軸) | π₀ | AE側(MoE) | 位置 | 位置制御 |
| OmniVTLA[4] | RGB×2 | 触覚画像+トルクセンサ | π₀ | VLM側(Enc有) | 位置 | 位置制御 |
| Tactile-VLA[8] | RGB | トルクセンサ | π₀ | VLM側(Enc有) | 位置+目標力 | 力補正付き |
| TA-VLA[7] | RGB×3 | 関節トルク | π₀ | AE側(MLP) | 位置+将来トルク | 位置制御 |
| VTLA[9] | RGB×1 | 触覚画像 | Qwen2-VL | VLM側(Enc有) | 位置 | 位置制御 |
| ForceMimic[10] | 点群 | トルクセンサ | 拡散ポリシー | — | 位置+6軸力 | ハイブリッド |
| VLA-Touch[11] | RGB×2 | 触覚画像 | RDT-1B | VLM側(Enc無*3) | 位置 | 位置制御 |
| Bi-ACT/LAT[2][3] | RGB×2 | 関節トルク | ACT | 直接結合 | 角度+角速度+トルク | ハイブリッド |
*3 VLA-Touchは触覚を言語化(VLA未改変)
力情報のセンシング
サーベイ対象の研究では、力情報の取得方法は大きく3種類に分かれます。
関節トルク
モーターからトルクを直接取得、または推定する方式です。
モーター電流や外乱オブザーバからトルクを推定します。TA-VLA[7]は電流の定数倍をトルクとし、Bi-ACT/LAT[2][3]は外乱オブザーバにより実トルクを推定しています。追加ハードウェアが不要で低コスト・導入が容易な反面、ノイズ・熱ドリフトの影響を受けやすく、接触位置の情報は得られません。
触覚画像

GelSight等の外部接触センサを用いて、接触面の変形を2D画像データとして取得する方式です。
OmniVTLA[4]はGelSight、VTLA[9]はGelStereo 2台、VLA-Touch[11]はGelSight Miniをそれぞれ使用しています。高空間解像度で接触状態を詳細に把握できる一方、時間解像度が低く(20〜30Hz)、コスト・摩耗・形状面の制約があります。
トルクセンサ
外部センサまたはロボット内蔵の推定機能から、力・トルクの数値を直接取得する方式です。
ForceVLA[1]はFlexivの内蔵推定値、ForceMimic[10]は外付6軸センサの実測値、Tactile-VLA[8]は法線力とせん断力、OmniVTLA[4]は力覚ベースの触覚センサであるPaxiniをそれぞれ用いています。高時間解像度(〜1 kHz)で6DoF(6自由度)の情報が得られますが、専用センサが必要でコストが高く、推定値の場合は精度に限界があります。
モデルのアーキテクチャ
サーベイ対象の多くはπ₀やACT等の既存モデルを拡張し、力情報の入出力を追加しています。
π₀(Physical Intelligence, 2024)[5]

- エンコーダ(SigLiP)
RGB画像をトークン列に変換する
- VLM(PaliGemma 3B)
画像トークンと言語指示を統合し「何をすべきか」を理解する
- Action Expert
300M パラメータのデコーダ。VLM出力を条件にFlow Matchingで 一定ステップのアクションチャンクを生成する
ACT(Action Chunking with Transformers)[6]
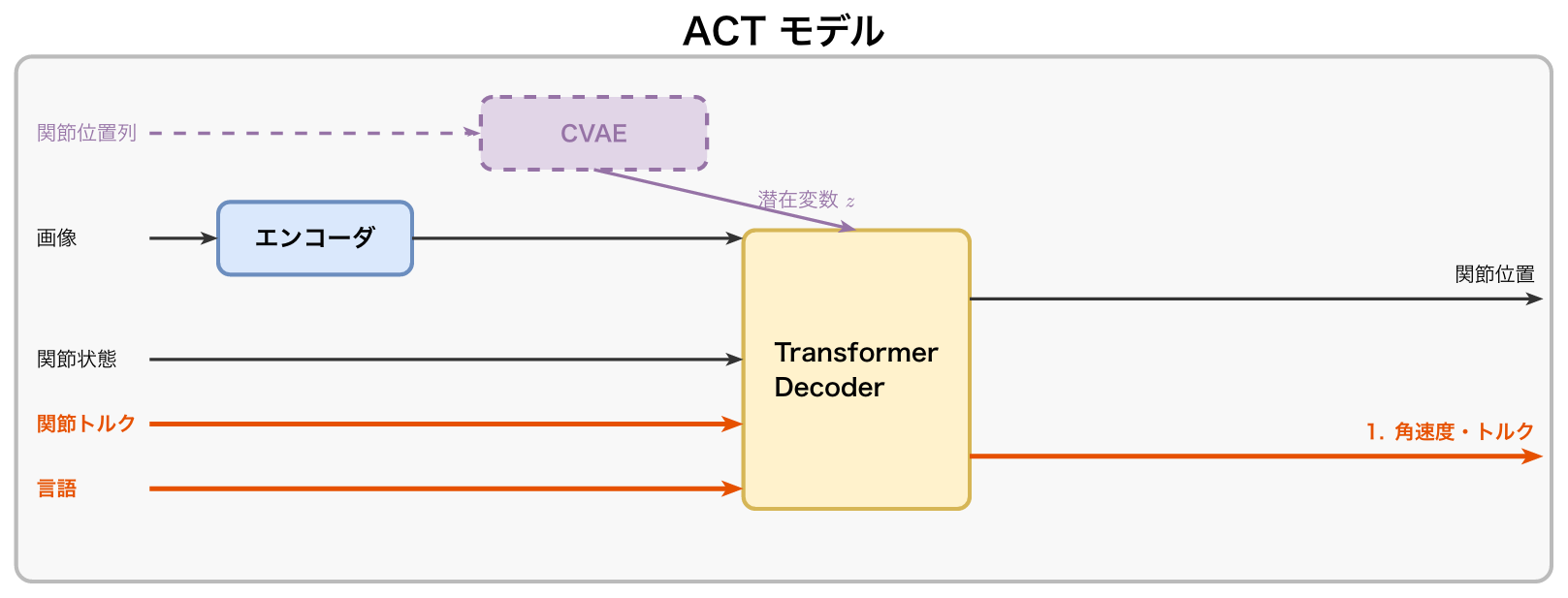
- エンコーダ(ResNet18)
RGB画像(ACT:4枚、Bi-ACT:2枚)を特徴マップに変換する
- CVAE(学習時のみ)
人間のデモには「同じ状況でも異なる軌道を取る」ばらつきがあるため、それを潜在変数zで吸収する。推論時はz=0に固定
- Transformer Decoder
画像特徴・関節状態・潜在変数zから、次のkステップ分の関節位置をまとめて予測する(アクションチャンク)。重複するチャンクは指数加重平均で結合し、動きをなめらかにする
力情報の入力方法
力情報をモデルのどこに入力するかは、大別すると「VLM側に入力する方法」と、「デコーダ(Action Expert)側に入力する方法」の2系統に分かれます。「デコーダ(Action Expert)側に入力する方法」は、どのように力情報とその他のモーダルを融合するかによって細分化されます。

- VLM側(図①)
力覚データ(触覚画像やセンサ値)をトークン化しVLMへ入力する方式です。OmniVTLA[4]/Tactile-VLA[8]/VTLA[9]が採用しています。力なしに比べ性能は上がりますが、「デコーダ(Action Expert)側に入力する方法」ほどの改善は得られていないとされています(ForceVLA[1]では45% → 55%)。
- デコーダ側
-
VLMを通した後のデコーダ入力段階で力情報を統合する方式です。融合の仕方によってさらに分かれます。
入力位置による性能差
「VLM側に入力する方法」でもベースラインより改善しますが、「デコーダ(Action Expert)側に入力する方法」の方が一貫して高い性能を示すとされています。
- TA-VLA[7]
「MLP:多層パーセプトロンを用いる方式」が最も高く、「直接結合する方式」、「VLM側に入力する方法」の順に性能が下がる
- ForceVLA[1]
「MoE:混合エキスパートを用いる方式」(80%)が最も高く、「直接結合する方式」(60%)、「VLM側に入力する方法」(55%)、ベースライン π₀(45%)の順
「デコーダ(Action Expert)側に入力する方法」が優位な理由として、両論文から以下の知見が得られています。
ForceVLA[1]ではVLMは大規模データで事前学習しているため、「VLM側に入力する方法」のように力トークンをVLMの入力に加えると、学習済みの特徴を壊してしまいやすいためです。実際、MoEをVLMの前に置くと成功率が0%となりました。
TA-VLA[7]ではトルクと関節角度はどちらも関節レベルの信号であり、統計的にも類似性が高いことが確認されています。またデコーダはエンコーダより入力の小さな変動に敏感であるため、力の微細な変化を拾うにはデコーダ側に統合する方が有効に働くとされています。
| 融合方式 | 成功率 |
|---|---|
| ベースライン(π₀) | 45% |
| VLM側に入力する方法 … 力を線形射影しVLM入力に追加 | 55% |
| 直接結合する方式 | 60% |
| MoE:混合エキスパートを用いる方式 … 4エキスパートMLP+Top-1ルーティングで動的融合 | 80% |
| 融合方式 | ボタン押し | 充電器挿入 |
|---|---|---|
| π₀(ベースライン) | 45/20 | 0/20 |
| VLM側に入力する方法 … Enc | 7/20 | 8/20 |
| 直接結合する方式 … DePre | 8/20 | 11/20 |
| MLP:多層パーセプトロンを用いる方式 … DePost | 10/20 | 12/20 |
制御方式
モデル出力をロボットの動作に変換する制御方式は、「位置のみを出力し位置制御で駆動する方式」と、「位置に加え力も出力し力制御・ハイブリッド制御を組み合わせる方式」の2つに大別されます。
位置出力 → 位置制御
力情報は入力のみで活用し、出力は目標姿勢のみとする方式です。ForceVLA[1]/OmniVTLA[4]/VTLA[9]/VLA-Touch[11]が採用しています。TA-VLA[7]では位置に加え将来トルクも同時に予測させることで力応答の因果関係を学習していますが、予測値は制御には使用しません。
位置+力出力
位置だけでなく力情報も出力し、直接制御や制御の補正に用いる方式です。力の使い方によってさらに分かれます。
- 力補正付き位置制御
-
Tactile-VLA[8]ではモデルが目標力も出力し、実測力との誤差が閾値を超えたときのみ位置を補正する
- ハイブリッド制御
-
ForceMimic[10]では 位置と6軸力を同時に出力する。
予測力が小さいとき(6N未満)は位置制御のみ、大きくなると軸ごとに位置と力を分けて制御する。1kHzのF/Tセンサにより高精度な力制御が可能で、皮むき時の接触力を ~20N → ~9N に抑制し成功率が向上(55% → 85%)
- バイラテラル制御
-
Bi-ACT/LAT[2]では角度・角速度・トルクをaction chunkとして予測し、バイラテラル制御(リーダとフォロワーの位置一致+トルクの作用反作用)でモータ電流に変換する。
DOB/RFOBにより力センサ不要(制御1kHz、推論100Hz)。力ありモデルでは複雑形状の物体の成功率が大幅に向上している(接着剤ボトル 80% vs 50%、アイクリーム 100% vs 50%)。Bi-LATは言語エンコーダ(SigLIP)を追加し、自然言語指示で把持力の強弱を制御可能にした拡張
まとめ
VLAモデルに力情報を統合するVTLA研究を、力のセンシング方法・モデルのアーキテクチャ・制御方式の3つの観点で整理しました。
残された課題
VLA、VTLAや弊社製品にご興味がありましたら、まずはお気軽にご連絡ください。
参考文献
- [1] J. Yuら, ForceVLA: Enhancing VLA Models with a Force-aware MoE for Contact-rich Manipulation, arXiv:2505.22159, https://arxiv.org/abs/2505.22159
- [2] T. Buamaneeら, Bi-ACT: Bilateral Control-Based Imitation Learning via Action Chunking with Transformer, arXiv:2401.17698, https://arxiv.org/abs/2401.17698
- [3] T. Kobayashiら, Bi-LAT: Bilateral Control-Based Imitation Learning via Natural Language and Action Chunking with Transformers, arXiv:2504.01301, https://arxiv.org/abs/2504.01301
- [4] Z. Chengら, OmniVTLA: Vision-Tactile-Language-Action Model with Semantic-Aligned Tactile Sensing, arXiv:2508.08706, https://arxiv.org/abs/2508.08706
- [5] K. Blackら, π₀: A Vision-Language-Action Flow Model for General Robot Control, arXiv:2410.24164, https://arxiv.org/abs/2410.24164
- [6] T. Z. Zhaoら, Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware, arXiv:2304.13705, https://arxiv.org/abs/2304.13705
- [7] Z. Zhangら, TA-VLA: Elucidating the Design Space of Torque-aware Vision-Language-Action Models, arXiv:2509.07962, https://arxiv.org/abs/2509.07962
- [8] J. Huangら, Tactile-VLA: Unlocking Vision-Language-Action Model’s Physical Knowledge for Tactile Generalization, arXiv:2507.09160, https://arxiv.org/abs/2507.09160
- [9] C. Zhangら, VTLA: Vision-Tactile-Language-Action Model with Preference Learning for Insertion Manipulation, arXiv:2505.09577, https://arxiv.org/abs/2505.09577
- [10] W. Liuら, ForceMimic: Force-Centric Imitation Learning with Force-Motion Capture System for Contact-Rich Manipulation, arXiv:2410.07554, https://arxiv.org/abs/2410.07554
- [11] J. Biら, VLA-Touch: Enhancing Vision-Language-Action Models with Dual-Level Tactile Feedback, arXiv:2507.17294, https://arxiv.org/abs/2507.17294



