BigQueryのデータをグラフ等などに集計する場合、DataStudioなどのBIツールを用いるのが一般的だと思います。
しかし、どういった情報をグラフにするかを検討する段階においてはDataStudioだとまどろっこしく感じることもあると思います。
本記事ではBigQueryのデータをGoogleスプレッドシートを用いたお手軽に検証する手順を紹介します。記事に用いるデータは開発用アカウントのものです。
想定読者
- BigQueryのデータをグラフにしたい
- BIツールを利用するほどではなく、まずはぱっとデータを見てみたい
データ連携の方法
主に3つの手段がデータ連携にはあります。
- テーブルをスプレッドシートと連携する。
- BigQuery上で実行したクエリの結果をスプレッドシートに保存する
- データ探索を用いてBigQueryとシートを接続する
さらに2については2つの手段があります。
- 実行結果をスプレッドシートに出力する(10MBまで)
- 実行結果をCSVとしてドライブに出力し、スプレッドシートで開く(上限の1GBまで)
以下では、このうちのいくつかをそれぞれの手順について解説します。
方法1:テーブルをスプレッドシートと連携する
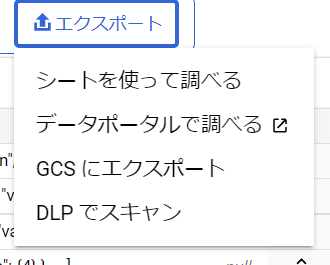
こちらの手順は非常に簡単です。
BigQueryのコンソールで集計したいテーブルを開きます。
上部ツールバーにあるエクスポートの「シートを使って調べる」を選択します。
下記のようにテーブルで集計が可能になります。
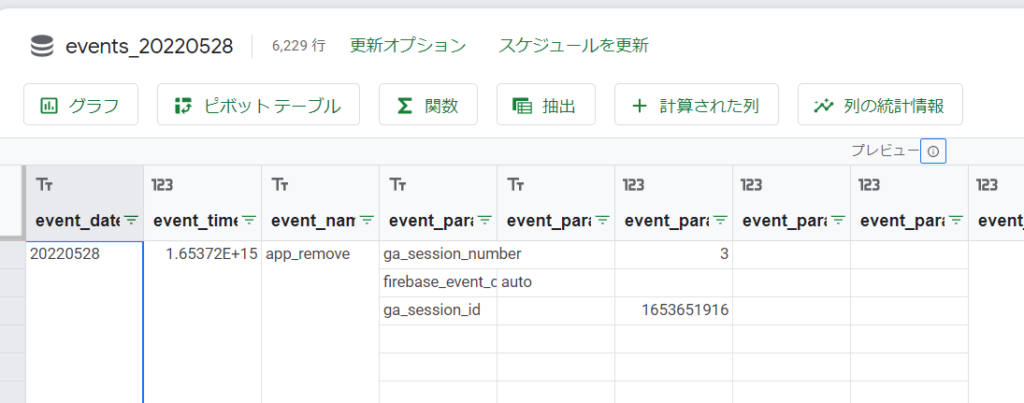
試しに「sceen_view」イベントの画面表示数を集計します。
「ピボットテーブル」を選択し、「新しいシート」を選択し作成します。

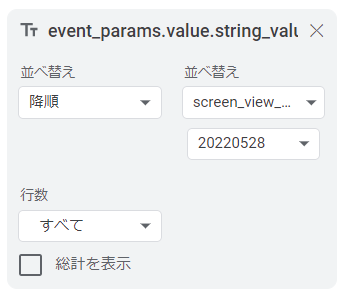
「行に「event_params.value.string_value」を設定します。
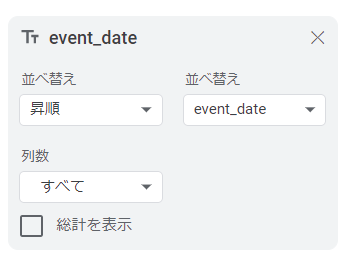
列に「event_date」を指定します。
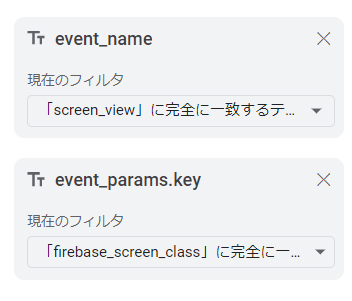
フィルタに「event_name」で「screen_view」を指定し、「event_params.key」に「firebase_screen_class」を指定します。
最後に値として計算フィールドを指定します。集計をカスタムに変更し、「COUNT(event_params.value.string_value)」と数式を入力します。「計算フィールド名」に任意の名前を設定します(「screen_count」としました)。
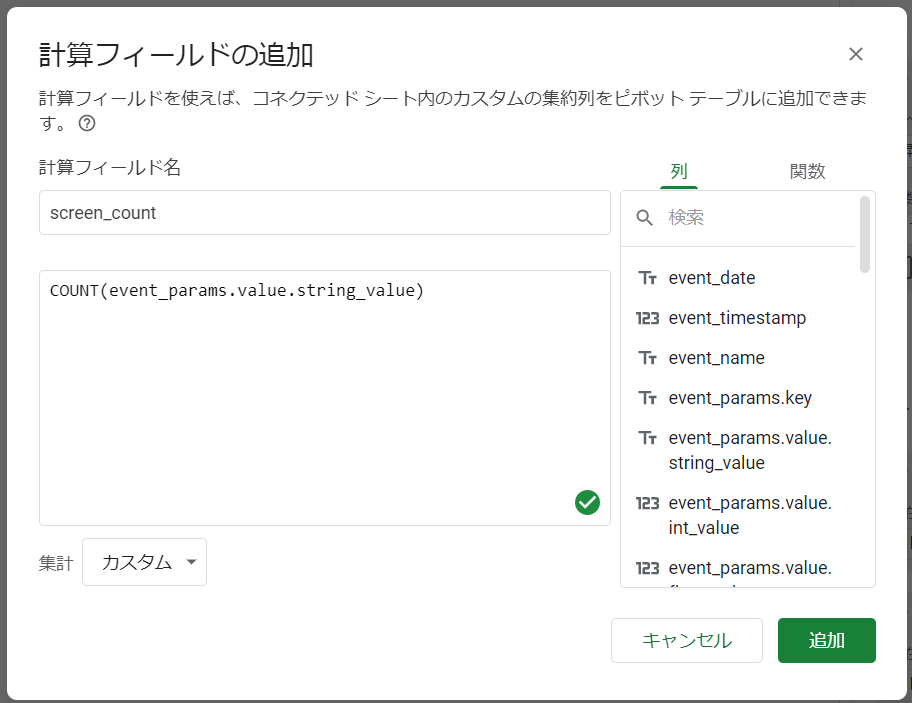
これで集計の準備が整いました。テーブル上の更新ボタンを押して集計完了です。
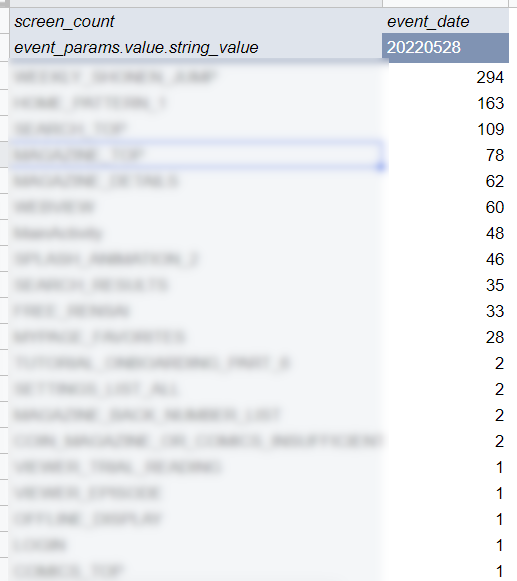
次のように表の生成が行えます。
あとは通常の手順でグラフを作成することができます。
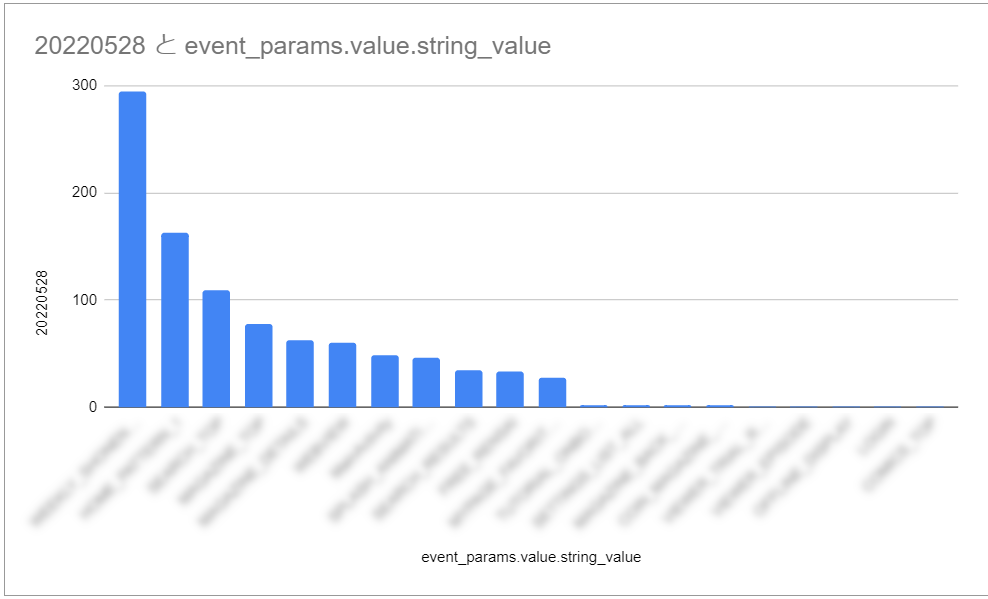
このようにテーブル連携を用いるとBigQueryにエクスポートしたGAのイベントなどを簡単に集計することが可能です!
方法2:BigQuery上で実行したクエリの結果をスプレッドシートに保存する
データサイズが一定サイズ(10MBまたは1GB)以下の場合はスプレッドシートに出力し、データを操作することが可能です。CSVの場合は1GBまでと大きな結果も扱うことができます。
1.実行結果をスプレッドシートに出力する
結果が10MB以下の場合に利用可能です。手順は下記の通りです。
まずは任意のSQLを実行し結果を得ます。サンプルでは下記SQLのように日付ごとに画面を表示したユニークユーザー数とその割合を集計します。割合を集計するのは日付間で比較可能にするためです。
DECLARE date_start STRING DEFAULT "0606";
DECLARE date_end STRING DEFAULT "0610";
WITH
screen_view AS (
SELECT
event_date,
screen.value.string_value screen_name,
COUNT(DISTINCT user_id) uu_count
FROM
`r-prototype.analytics_211026204.events_2022*`,
UNNEST(event_params) screen
WHERE
_TABLE_SUFFIX BETWEEN date_start AND date_end
AND event_name = "screen_view"
AND screen.key = "firebase_screen_class"
GROUP BY
1,
2)
SELECT
event_date,
screen_name,
uu_count,
(uu_count / (
SELECT
MAX(t1.uu_count)
FROM
screen_view t1
WHERE
t1.event_date = screen_view.event_date)) uu_count_percent
FROM
screen_view
実行後は「結果を保存する」の「Googleスプレッドシート」を選択し、シートに出力します。
出力されたスプレッドシートを開き、テーブルを連携したときと同様にピボットテーブルを用いて操作を行います。
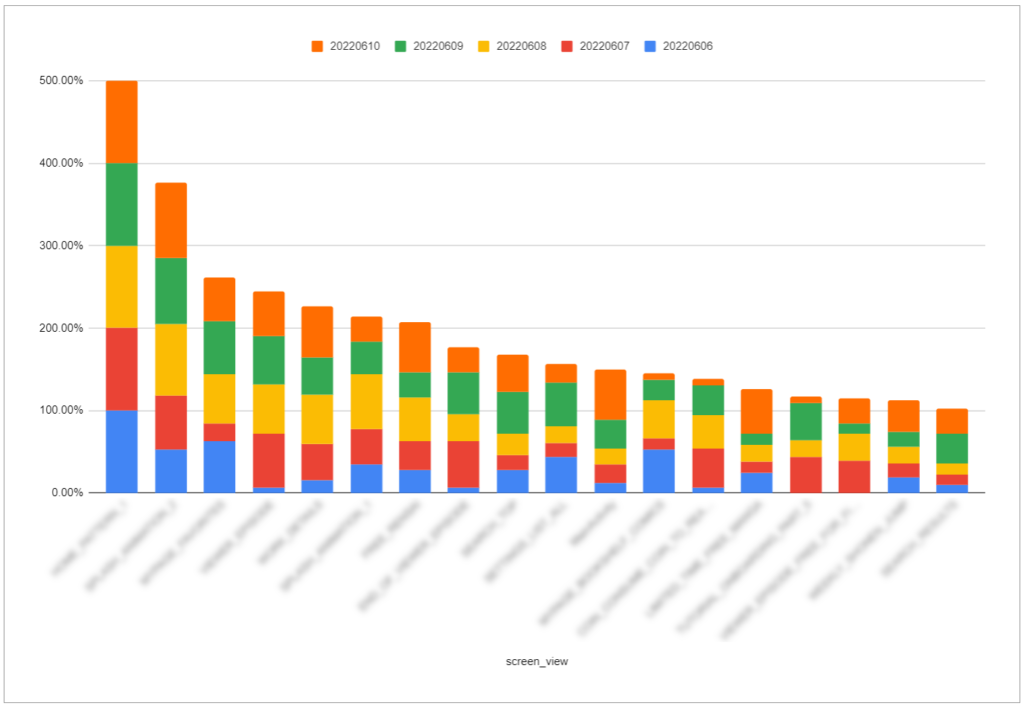
今回の例では下記のように行には「screen_name」を指定し、列に「event_date」、値に「uu_count_percent」を指定します。日付間で比較する場合に絶対数で比較はできないので比率を利用します。

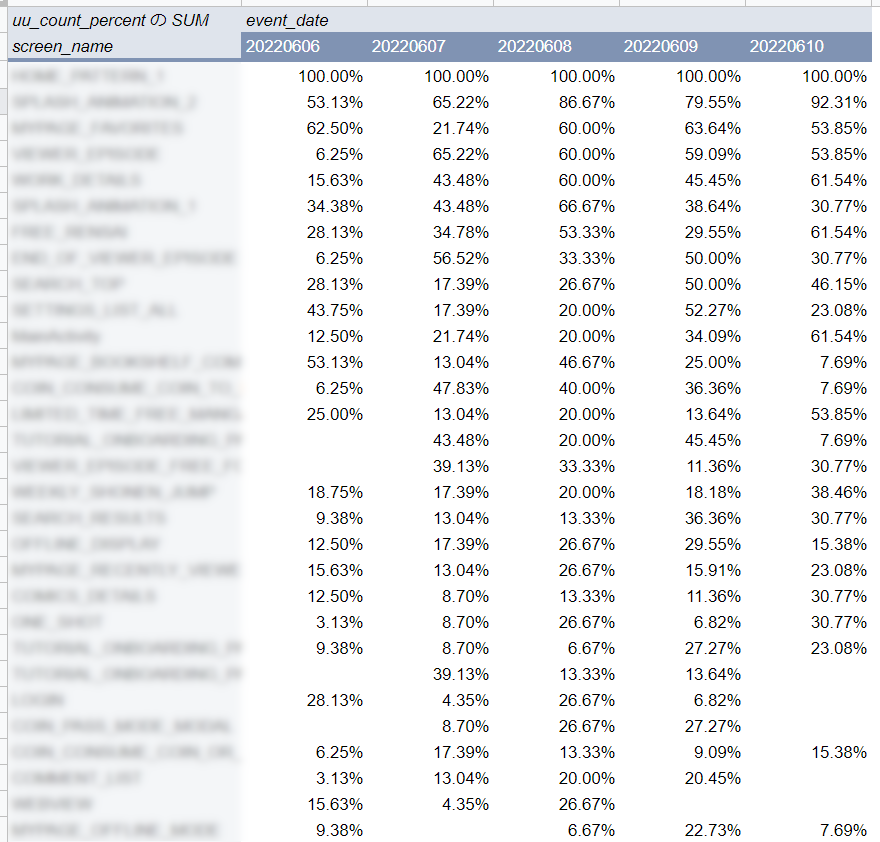
ピボットテーブルにより下記のように表が得られます。
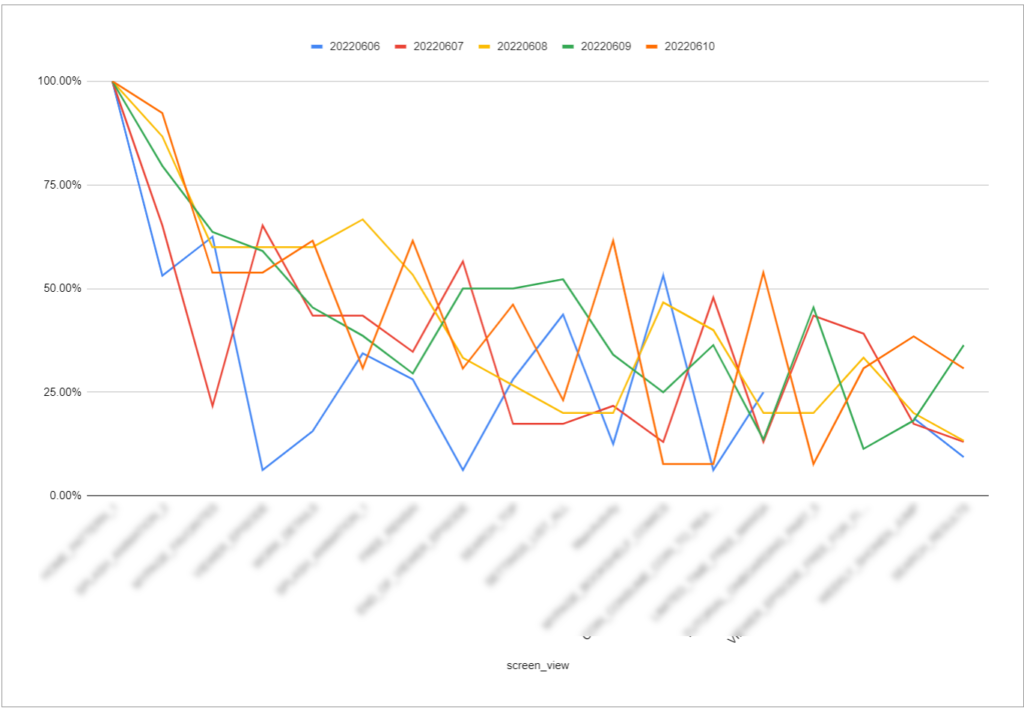
最後にグラフにすることで下記のように日付毎の変化の違いを視覚的に確認することができます。
2.実行結果をCSVとしてドライブに出力し、スプレッドシートで開く
スプレッドシートへの出力は10MBまでですが、CSVとしてGoogleドライブに出力し、スプレッドシートに変換することで上限を超え、スプレッドシートの上限である1GBまで扱うことができます。
ただし、行数が大きい状態でピボットテーブルを用いる場合はピボットテーブルが扱える上限を超えてしまうことがあります。その場合はフィルタの条件を調整しデータ量を抑える必要があります。
手順は下記の通りです。

CSVに保存する手順はスプレッドシートと同様に「結果を保存する」を選択し、「CSV(Googleドライブ)」を選択します。

エクスポート後にドライブでCSVを「Googleスプレッドシート」で開くことで同様に集計することができます。
方法3:データ探索を用いてBigQueryのクエリとシートを接続する
クエリを逐次実行して比較をしたい場合などは結果をシートに保存する方法だとBigQuery上で都度実行し、シートに保存する手順を踏むことになり手間がかかります。
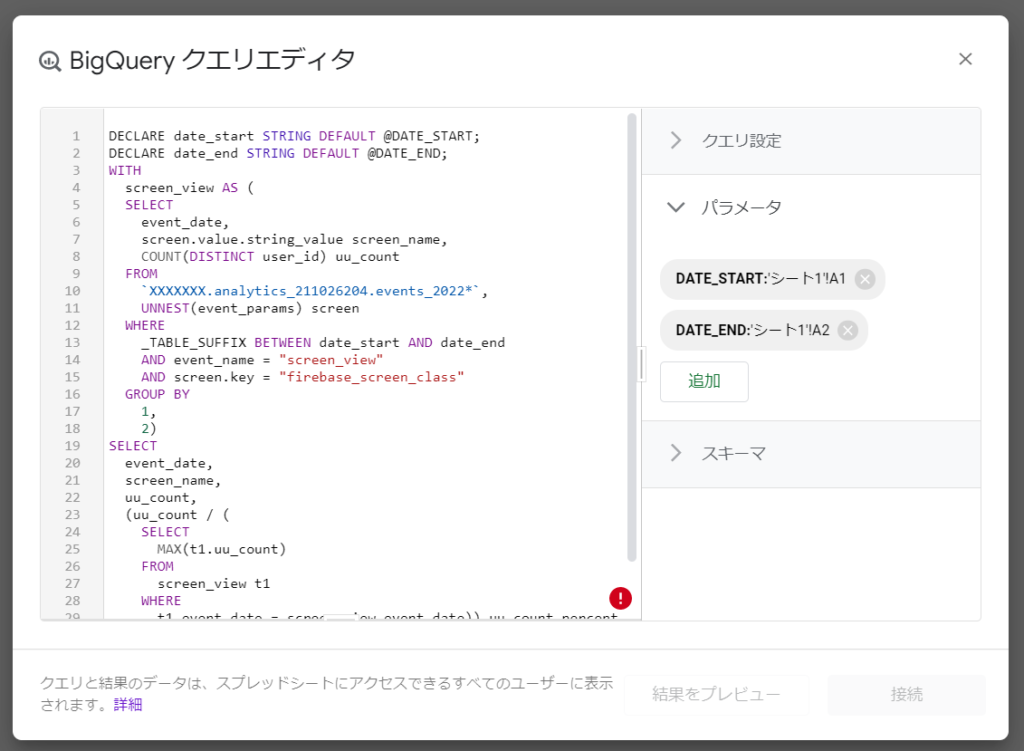
下記の「シートを使って調べる」を用いることでBigQueryのクエリと接続した状態で集計が可能になります。
クエリの内容は、下記の「接続設定」から変更可能です。
※「DECLARE」を利用している場合に接続エラーになる場合があります。その場合は手動でクエリエディタを開いて「DECLARE」を補完する必要があります。
下記のように確認ができます。またシートのセルからパラメータを取得するようにもできます。
実行した結果を保存したい場合は上部ツールバーにある「抽出」を実行することで可能です。
大変便利な「シートを使って調べる」の機能ですが、注意点としては「接続シート」から作成したピボットテーブルは条件を変更するたびにクエリが実行されます。処理量が大きいクエリは都度料金がかかるので注意が必要です。
まとめ
本記事ではBigQueryで集計したデータをGoogleスプレッドシートを利用して可視化する手順を紹介しました。
どういったデータなのか、どういった集計が有効かを調査する場合に簡単に集計することができます。
このようにいくつかの方法でスプレッドシートを用いた簡易的な分析が行えます。
執筆者:久保


