手元の学習データや解決したいタスクに最適な機械学習モデルを迅速に見つけたい。様々な機械学習モデルのトレーニングを行い性能の比較をしたい。そんな時に役にたつのが、機械学習の自動化 (Automated Machine Learning, AutoML) です。
本記事では AutoML で何ができるのか紹介し、テーブルデータを題材に Python で利用できる AutoML ライブラリの使用例を解説します。
- Contents -
AutoML とは
AutoML とは、通常は人間の手で行なわれる機械学習モデルの開発を、文字通り自動化することを指します。
AutoML で自動化される範囲としては、機械学習モデルの開発における以下に示す工程が挙げられます。
- データの前処理、クリーニング
- 適切な特徴量の選択と作成(特徴量エンジニアリング)
- モデルの学習
- ハイパーパラメータ最適化
- モデルの学習- ハイパーパラメータ最適化
- モデルの性能評価と最適なモデルの選択
- モデルのアンサンブル
これらの作業には専門的な知識や作業コストが要求されるというハードルがありますが、AutoML を利用することで、最小限の労力と機械学習の専門知識で、高品質のカスタム機械学習モデルを作成できるようになります。
したがって AutoML は、機械学習の知識を持たない人でも、高性能な機械学習モデルの構築を可能にすると期待されている技術です。
現在、様々な AutoML のライブラリが開発されています。各ライブラリごとに扱えるデータの種類、前処理手法、モデルアルゴリズム、アンサンブル手法等が異なっています。
auto-sklearn
auto-sklearn は、機械学習ライブラリの scikit-learn を中心に構築された AutoML のライブラリです。University of Freiburg, Germany の Feurer らによって 2015 年に発表され (参考) 開発されています。2020 年に Auto-Sklearn 2.0 が発表されており (参考)、experimental 版ですがライブラリでも使えるようになっています (参考)。
ここでは、auto-sklearn を使った AutoML の実行例を追いながら、解説します。なお、Python コード自体の詳細な説明は、本記事では扱いませんが、Google Colaboratory 上で実行できるようにコードを公開していますので、手元で試されたい場合はこちらをご参照ください (参考)。
利用例の題材(タイタニックデータセット)
本記事では、テーブルデータの分類問題を AutoML を使って解いてみることにします。
タイタニックデータセットは、タイタニック号沈没事故 における乗員の生存状況の情報を含むデータセットです。1309件の「表形式データ(年齢や性別などの13項目)」と「ラベル(生存状況)」から構成されます。各乗員の特徴から生存者を予測するタスクが、機械学習の例題として、よく利用されています。著名なデータ分析コンペの Kaggle では、チュートリアルで使われています。
以降では AutoML を使って、タイタニック号の乗員が生存したかどうかを予測することを目指します。
トレーニングの実行
auto-sklearn で分類問題タスクを解く場合、下記のようにモデルのトレーニングを実行できます。
import autosklearn.classification
model = autosklearn.classification.AutoSklearnClassifier(
metric=autosklearn.metrics.accuracy, # 評価関数
time_left_for_this_task=120, # トータルの時間制限 (秒)
per_run_time_limit=30, # モデルごとの時間制限 (秒)
memory_limit=3072, # メモリ使用量制限 (MB)
# デフォルトの設定は 'holdout', 'train_size'=0.67
resampling_strategy='holdout', # 検証データの分割法
resampling_strategy_arguments={'train_size': 0.67}, # 分割パラメータ
n_jobs=1, # 実行 CPU コア数
seed=2, # シード
ensemble_size=50 # 最終的なアンサンブルに含まれるモデルの最大数
)
model.fit(X_train, y_train, X_test, y_test)ここで、model.fit() 関数に渡されているデータは下記の通りです。
X_train: 学習データの入力
y_train: 学習データの正解ラベル
X_test: テストデータの入力
y_test: テストデータの正解ラベル
X_test, y_test は学習時には必須ではありませんが、指定することで学習の途中にそのテストデータセット に対する評価を実行して記録することができます。
トレーニング実行時の auto-sklearn の主要な設定に関して、以下で解説します。
評価関数(メトリクス)
モデルの性能評価に使われるメトリクスを指定します。指定しなかった場合は、タスクごとに異なるデフォルトのメトリクスが設定されます。
今回の実行例では、正解率(accuracy)を指定しています。
実行時間とメモリ使用量の制限
AutoML では、時間をかければかけるほど多くのモデルとパラメータの組み合わせを探索できるため、より性能の良いモデルを発見しやすくなります。しかし、ずっと待っているわけにもいかないので、実行時間を設定してその範囲内でベストなモデルを最終的な結果とします。つまり、使用できるリソースの制限は、最適化の実行時間とテストできるモデルの数とのトレードオフの関係にあります。
実行時間制限に関しては、明確なガイドラインを作成することは難しいですが、トータルで 1 日、1 つのモデルごとの実行時間で 30 分の制限が推奨されています (参考)。
メモリ使用量の制限はデフォルトで 3GB に設定されています。データセットの大きさに依存しますが、3GB または 6GB で十分なことがほとんどです。もし、実行中にメモリ制限に到達した場合は、その時点でトレーニングが停止されます (参考)。
今回の実行例では、デモンストレーションが目的のため、トータルで 2 分、1 つのモデルごとの実行時間で 30 秒の制限を指定しています。メモリ使用量の制限は、デフォルト値を指定しています。
探索空間の制限
auto-sklearn が探索対象のモデルアルゴリズムや前処理方法を制限することができます。探索の必要がないアルゴリズムが分かっていれば、探索対象から除外することで、それ以外のアルゴリズムを効率的に探索できます。また、特定のアルゴリズムのみに絞って探索することも可能です。
前処理方法の探索は行わないような制限も可能です。前処理方法のみ自前でやる場合やモデルのみ探索したい場合に使うと良さそうです。明らかに予測結果に影響を与えない特徴量があれば、予め手動で除去しておくことで、探索空間が狭められるため AutoML が最適なモデルを見つけやすくなります。 例の notebook では、チケット番号や乗客の名前といった、事故生存とは明らかに無関係な特徴量は手動で削除しています。
auto-sklearn では、get_configuration_space() 関数 を利用することで、予め探索される設定空間を把握することができます。
今回の実行例では、特に探索空間に制限は設けずに実行します。
検証のためのデータ分割方法の選択
auto-sklearn が複数のモデルを比較する際に、学習と検証のために元々の入力データセットを分割します。よく使われるもので「ホールドアウト法」がありますが、いくつかの分割方法 (resampling strategies) がサポートされています。
デフォルトでは、ホールドアウト法で、全体の 67% のデータが学習に、33% のデータが検証に使われます。
サポートされている分割方法の他に、独自の分割方法を選択することも可能です。詳細はドキュメントをご参照ください。
今回の実行例では、デフォルトの設定で実行します。
アンサンブル
アンサンブルとは、複数のモデルを組み合わせてモデルを作ること、もしくは予測を行う方法です。アンサンブルによって、モデル性能の向上が見込まれます。一方で複数のモデルを利用するため、単一のモデルのみ利用する場合に比べて、計算コストが高くなるデメリットもあります。シンプルなアンサンブルの方法としては、複数のモデルの予測値の平均をとる方法が挙げられます。
auto-sklearn では Caruana et al. (2004) が発表した手法を使って、検証データセットに対する予測性能をベースにモデルアンサンブルを構築しています。アンサンブル構築に関連するハイパーパラメータ (ensemble_size) を使って、アンサンブルに含めるモデルの数を指定できます。
今回の実行例では、デフォルトの設定で実行します。
結果を確認する
正解率
auto-sklearn を使った学習結果を確認していきます。
学習データとテストデータに対する正解率は下記のように確認できます。
s = model.score(X_train, y_train)
print(f"Train score {s}")
s = model.score(X_test, y_test)
print(f"Test score {s}")Train score 0.9050218340611353
Test score 0.7938931297709924今回の結果では、学習データに対して 0.905、テストデータに対して 0.794 の正解率となりました。探索時間の制限をもっと長くすることで、性能向上は見込まれます。
アルゴリズム探索の統計
下記のように、アルゴリズムの探索結果を確認することができます。
print(model.sprint_statistics())auto-sklearn results:
Dataset name: titanic_example
Metric: accuracy
Best validation score: 0.825083
Number of target algorithm runs: 25
Number of successful target algorithm runs: 23
Number of crashed target algorithm runs: 0
Number of target algorithms that exceeded the time limit: 2
Number of target algorithms that exceeded the memory limit: 0今回はそれぞれのアルゴリズムで 30 秒を制限時間として設定しましたが、2 個のアルゴリズムが時間制限を超えてしまっていることがわかります。学習に成功したアルゴリズムは合計 23 個で、validation データ (学習時に自動で resampling strategies により入力データを分割して作成される) に対するベストスコアは 0.825 となっています。
ベストモデルと個別のモデルの確認
探索されたそれぞれのアルゴリズムの詳細は下記のように、leaderboard() 関数で確認できます。detailed=True を指定することで、より詳細に確認できます。
model.leaderboard(detailed=False, ensemble_only=True, sort_by='cost')
rank が探索されたモデルの順位、cost は validation データセットに対するロス(今回の場合、1 – accuracy)を意味しています (参考)。ensemble_weight は、最終的なアンサンブルの中で、それぞれのモデルに割り当てられた重みです。単体では、ランダムフォレストが最も性能が良いモデルであるということが確認できました。
個別の重みとモデルは get_models_with_weights() 関数で取得できます。 下記のように、単体のモデルを取り出して予測することが可能です。 ランダムフォレストモデルを取り出して、テストデータに対する正解率を出しています。
list_models = model.get_models_with_weights()
model_rf = list_models[6][1]
model_rf.score(X_test, y_test.astype("int"))0.7913486005089059単体で最も性能が良かったモデルの正解率 0.791 となりました。アンサンブルが 0.794 だったので、アンサンブルのほうが高くなっています。
一方で、推論速度はアンサンブルより単体のモデルの方が早いです。これは、アンサンブルの場合複数のモデルで推論を行なった上で最終的な結果を出すためです。下記は、アンサンブルと単体で推論を 10 回繰り返して速度を測定した結果です。
%%time
for i in range(10):
y_pred = model.predict(X_test)CPU times: user 8.28 s, sys: 2.26 s, total: 10.5 s
Wall time: 7.71 s%%time
for i in range(10):
y_pred_rf = model_rf.predict(X_test)CPU times: user 882 ms, sys: 3.96 ms, total: 885 ms
Wall time: 874 ms単体のモデルがアンサンブルより、約 10 倍速いことがわかります。
したがって、アンサンブルを使うかどうかは推論速度とモデルの性能のトレードオフの関係にあります。推論速度が許容範囲にあるのか、すこしの性能向上のために推論速度を犠牲にしてよいのか、ユースケースに合わせて決める必要があります。
モデルの説明
機械学習モデルはブラックボックスになりやすく、近年、モデルの説明性、解釈性が注目されて来ています(参考)。
モデル解釈のための機能として、auto-sklearn では scikit-tlearn の inspect module を使って、何が予測値に影響を与えているかを確認することができます。
下記は、permutation importance をプロットした図です。permutation importance は、特徴量の値を入れ替えたときの性能の変化を見ることで特徴量の有用性を計る手法です。
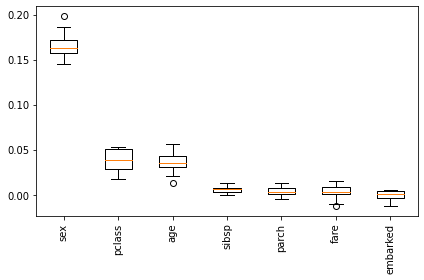
sex (性別) が最も有用性が高く、次点が pclass (乗客のクラスで社会経済的地位を示す) であることがわかります。したがって、性別と社会経済的地位が、事故生存と強く関係していると言えます。
他の AutoML ライブラリ
auto-sklearn 以外にも、様々な OSS の AutoML ツールが公開されています。それぞれ扱うアルゴリズムやデータの種類が異なっています。ここでは、その中からいくつかピックアップしてご紹介します。
Auto-sklearn 2.0
現在、auto-sklearn 2.0 の experimental 版が提供されています。notebook に実行例を記載しています。 従来の auto-sklearn に比べて、2.0 の方がパフォーマンス面で優れていると報告されています(参考)。
AutoGluon
AutoGluon は AWS によって開発されている AutoML ライブラリです。テーブルデータ、画像、自然言語を対象に AutoML を実行できます。
タイタニックデータを対象にした、AutoGluon の利用例を下記の notebook で公開しています。
https://github.com/hnishi/hello-automl/blob/main/autogluon_titanic.ipynb
H2O
H2O AutoML は H2O.ai によって開発されている Java 製の AutoML ツールで、Python Interface が提供されています。モデル説明のための機能が充実していて、簡易にそれらを呼び出すことができます。
タイタニックデータを対象にした、H2O Python Module の利用例を下記の notebook で公開しています。
https://github.com/hnishi/hello-automl/blob/main/h2o_titanic.ipynb
まとめ
以上、ざっくりと AutoML で何ができるかをテーブルデータを題材にご紹介しました。従来は人間の手で様々なアルゴリズムや前処理手法を比較しながら試行錯誤してきましたが、今後は AutoML にお任せして、AutoML の結果をじっくり解析していくという流れが広まっていくかもしれません。
ただ注意点として、AutoML が便利だとしても、ある程度のデータ分析や機械学習の知識が必要とされることが多いです。例えば、AutoML には扱えるアルゴリズム、前処理、後処理に制限があるため、より良い性能を得るためには AutoML の守備範囲以外に人間の手を加えることで更に性能向上できる場合があります。
AutoML を上手く利用して、機械学習モデルを活用していきましょう。
執筆者:西上


